Isabelle Augenstein
2025
Evaluating Input Feature Explanations through a Unified Diagnostic Evaluation Framework
Jingyi Sun | Pepa Atanasova | Isabelle Augenstein
Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
Jingyi Sun | Pepa Atanasova | Isabelle Augenstein
Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
Explaining the decision-making process of machine learning models is crucial for ensuring their reliability and transparency for end users. One popular explanation form highlights key input features, such as i) tokens (e.g., Shapley Values and Integrated Gradients), ii) interactions between tokens (e.g., Bivariate Shapley and Attention-based methods), or iii) interactions between spans of the input (e.g., Louvain Span Interactions). However, these explanation types have only been studied in isolation, making it difficult to judge their respective applicability. To bridge this gap, we develop a unified framework that facilitates an automated and direct comparison between highlight and interactive explanations comprised of four diagnostic properties. We conduct an extensive analysis across these three types of input feature explanations – each utilizing three different explanation techniques–across two datasets and two models, and reveal that each explanation has distinct strengths across the different diagnostic properties. Nevertheless, interactive span explanations outperform other types of input feature explanations across most diagnostic properties. Despite being relatively understudied, our analysis underscores the need for further research to improve methods generating these explanation types. Additionally, integrating them with other explanation types that perform better in certain characteristics could further enhance their overall effectiveness.
SynDARin: Synthesising Datasets for Automated Reasoning in Low-Resource Languages
Gayane Ghazaryan | Erik Arakelyan | Isabelle Augenstein | Pasquale Minervini
Proceedings of the 31st International Conference on Computational Linguistics
Gayane Ghazaryan | Erik Arakelyan | Isabelle Augenstein | Pasquale Minervini
Proceedings of the 31st International Conference on Computational Linguistics
Question Answering (QA) datasets have been instrumental in developing and evaluating Large Language Model (LLM) capabilities. However, such datasets are scarce for languages other than English due to the cost and difficulties of collection and manual annotation. This means that producing novel models and measuring the performance of multilingual LLMs in low-resource languages is challenging. To mitigate this, we propose SynDARin, a method for generating and validating QA datasets for low-resoucre languages. We utilize parallel content mining to obtain human-curated paragraphs between English and the target language. We use the English data as context to generate synthetic multiple-choice (MC) question-answer pairs, which are automatically translated and further validated for quality. Combining these with their designated non-English human-curated paragraphs form the final QA dataset. The method allows to maintain content quality, reduces the likelihood of factual errors, and circumvents the need for costly annotation. To test the method, we created a QA dataset with 1.2K samples for the Armenian language. The human evaluation shows that 98% of the generated English data maintains quality and diversity in the question types and topics, while the translation validation pipeline can filter out ~70% of data with poor quality. We use the dataset to benchmark state-of-the-art LLMs, showing their inability to achieve human accuracy with some model performances closer to random chance. This shows that the generated dataset is non-trivial and can be used to evaluate reasoning capabilities in low-resource language.
Proceedings of the 3rd Workshop on Towards Knowledgeable Foundation Models (KnowFM)
Yuji Zhang | Canyu Chen | Sha Li | Mor Geva | Chi Han | Xiaozhi Wang | Shangbin Feng | Silin Gao | Isabelle Augenstein | Mohit Bansal | Manling Li | Heng Ji
Proceedings of the 3rd Workshop on Towards Knowledgeable Foundation Models (KnowFM)
Yuji Zhang | Canyu Chen | Sha Li | Mor Geva | Chi Han | Xiaozhi Wang | Shangbin Feng | Silin Gao | Isabelle Augenstein | Mohit Bansal | Manling Li | Heng Ji
Proceedings of the 3rd Workshop on Towards Knowledgeable Foundation Models (KnowFM)
Unstructured Evidence Attribution for Long Context Query Focused Summarization
Dustin Wright | Zain Muhammad Mujahid | Lu Wang | Isabelle Augenstein | David Jurgens
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Dustin Wright | Zain Muhammad Mujahid | Lu Wang | Isabelle Augenstein | David Jurgens
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Large language models (LLMs) are capable of generating coherent summaries from very long contexts given a user query, and extracting and citing evidence spans helps improve the trustworthiness of these summaries. Whereas previous work has focused on evidence citation with fixed levels of granularity (e.g. sentence, paragraph, document, etc.), we propose to extract unstructured (i.e., spans of any length) evidence in order to acquire more relevant and consistent evidence than in the fixed granularity case. We show how existing systems struggle to copy and properly cite unstructured evidence, which also tends to be “lost-in-the-middle”. To help models perform this task, we create the Summaries with Unstructured Evidence Text dataset (SUnsET), a synthetic dataset generated using a novel pipeline, which can be used as training supervision for unstructured evidence summarization. We demonstrate across 5 LLMs and 4 datasets spanning human written, synthetic, single, and multi-document settings that LLMs adapted with SUnsET generate more relevant and factually consistent evidence with their summaries, extract evidence from more diverse locations in their context, and can generate more relevant and consistent summaries than baselines with no fine-tuning and fixed granularity evidence. We release SUnsET and our generation code to the public (https://github.com/dwright37/unstructured-evidence-sunset).
Multi-Modal Framing Analysis of News
Arnav Arora | Srishti Yadav | Maria Antoniak | Serge Belongie | Isabelle Augenstein
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Arnav Arora | Srishti Yadav | Maria Antoniak | Serge Belongie | Isabelle Augenstein
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Automated frame analysis of political communication is a popular task in computational social science that is used to study how authors select aspects of a topic to frame its reception. So far, such studies have been narrow, in that they use a fixed set of pre-defined frames and focus only on the text, ignoring the visual contexts in which those texts appear. Especially for framing in the news, this leaves out valuable information about editorial choices, which include not just the written article but also accompanying photographs. To overcome such limitations, we present a method for conducting multi-modal, multi-label framing analysis at scale using large (vision-) language models. Grounding our work in framing theory, we extract latent meaning embedded in images used to convey a certain point and contrast that to the text by comparing the respective frames used. We also identify highly partisan framing of topics with issue-specific frame analysis found in prior qualitative work. We demonstrate a method for doing scalable integrative framing analysis of both text and image in news, providing a more complete picture for understanding media bias.
Specializing Large Language Models to Simulate Survey Response Distributions for Global Populations
Yong Cao | Haijiang Liu | Arnav Arora | Isabelle Augenstein | Paul Röttger | Daniel Hershcovich
Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
Yong Cao | Haijiang Liu | Arnav Arora | Isabelle Augenstein | Paul Röttger | Daniel Hershcovich
Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
Large-scale surveys are essential tools for informing social science research and policy, but running surveys is costly and time-intensive. If we could accurately simulate group-level survey results, this would therefore be very valuable to social science research. Prior work has explored the use of large language models (LLMs) for simulating human behaviors, mostly through prompting. In this paper, we are the first to specialize LLMs for the task of simulating survey response distributions. As a testbed, we use country-level results from two global cultural surveys. We devise a fine-tuning method based on first-token probabilities to minimize divergence between predicted and actual response distributions for a given question. Then, we show that this method substantially outperforms other methods and zero-shot classifiers, even on unseen questions, countries, and a completely unseen survey. While even our best models struggle with the task, especially on unseen questions, our results demonstrate the benefits of specialization for simulation, which may accelerate progress towards sufficiently accurate simulation in the future.
Presumed Cultural Identity: How Names Shape LLM Responses
Siddhesh Milind Pawar | Arnav Arora | Lucie-Aimée Kaffee | Isabelle Augenstein
Findings of the Association for Computational Linguistics: EMNLP 2025
Siddhesh Milind Pawar | Arnav Arora | Lucie-Aimée Kaffee | Isabelle Augenstein
Findings of the Association for Computational Linguistics: EMNLP 2025
Names are deeply tied to human identity - they can serve as markers of individuality, cultural heritage, and personal history. When interacting with LLMs, user names can enter chatbot conversations through direct user input (requested by chatbots), as part of task contexts such as CV reviews, or as built-in memory features that store user information for personalisation. In this work, we study name-based cultural bias by analyzing the adaptations that LLMs make when names are mentioned in the prompt. Our analyses demonstrate that LLMs exhibit significant cultural identity assumptions across multiple cultures based on users’ presumed backgrounds based on their names. We also show how using names as an indicator of identity can lead to misattribution and flattening of cultural identities. Our work has implications for designing more nuanced personalisation systems that avoid reinforcing stereotypes while maintaining meaningful customisation.
FLARE: Faithful Logic-Aided Reasoning and Exploration
Erik Arakelyan | Pasquale Minervini | Patrick Lewis | Pat Verga | Isabelle Augenstein
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Erik Arakelyan | Pasquale Minervini | Patrick Lewis | Pat Verga | Isabelle Augenstein
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Modern Question Answering (QA) and Reasoning approaches with Large Language Models (LLMs) commonly use Chain-of-Thought (CoT) prompting but struggle with generating outputs faithful to their intermediate reasoning chains. While neuro-symbolic methods like Faithful CoT (F-CoT) offer higher faithfulness through external solvers, they require code-specialized models and struggle with ambiguous tasks.We introduce Faithful Logic-Aided Reasoning and Exploration (FLARE), which uses LLMs to plan solutions, formalize queries into logic programs, and simulate code execution through multi-hop search without external solvers. Our method achieves SOTA results on 𝟕 out of 𝟗 diverse reasoning benchmarks and 3 out of 3 logic inference benchmarks while enabling measurement of reasoning faithfulness. We demonstrate that model faithfulness correlates with performance and that successful reasoning traces show an 18.1% increase in unique emergent facts, 8.6% higher overlap between code-defined and execution-trace relations, and 3.6% reduction in unused relations.
Explainability and Interpretability of Multilingual Large Language Models: A Survey
Lucas Resck | Isabelle Augenstein | Anna Korhonen
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Lucas Resck | Isabelle Augenstein | Anna Korhonen
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Multilingual large language models (MLLMs) demonstrate state-of-the-art capabilities across diverse cross-lingual and multilingual tasks. Their complex internal mechanisms, however, often lack transparency, posing significant challenges in elucidating their internal processing of multilingualism, cross-lingual transfer dynamics and handling of language-specific features. This paper addresses this critical gap by presenting a survey of current explainability and interpretability methods specifically for MLLMs. To our knowledge, it is the first comprehensive review of its kind. Existing literature is categorised according to the explainability techniques employed, the multilingual tasks addressed, the languages investigated and available resources. The survey further identifies key challenges, distils core findings and outlines promising avenues for future research within this rapidly evolving domain.
Graph-Guided Textual Explanation Generation Framework
Shuzhou Yuan | Jingyi Sun | Ran Zhang | Michael Färber | Steffen Eger | Pepa Atanasova | Isabelle Augenstein
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Shuzhou Yuan | Jingyi Sun | Ran Zhang | Michael Färber | Steffen Eger | Pepa Atanasova | Isabelle Augenstein
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Natural language explanations (NLEs) are commonly used to provide plausible free-text explanations of a model’s reasoning about its predictions. However, recent work has questioned their faithfulness, as they may not accurately reflect the model’s internal reasoning process regarding its predicted answer. In contrast, highlight explanations–input fragments critical for the model’s predicted answers–exhibit measurable faithfulness. Building on this foundation, we propose G-TEx, a Graph-Guided Textual Explanation Generation framework designed to enhance the faithfulness of NLEs. Specifically, highlight explanations are first extracted as faithful cues reflecting the model’s reasoning logic toward answer prediction. They are subsequently encoded through a graph neural network layer to guide the NLE generation, which aligns the generated explanations with the model’s underlying reasoning toward the predicted answer. Experiments on both encoder-decoder and decoder-only models across three reasoning datasets demonstrate that G-TEx improves NLE faithfulness by up to 12.18% compared to baseline methods. Additionally, G-TEx generates NLEs with greater semantic and lexical similarity to human-written ones. Human evaluations show that G-TEx can decrease redundant content and enhance the overall quality of NLEs. Our work presents a novel method for explicitly guiding NLE generation to enhance faithfulness, serving as a foundation for addressing broader criteria in NLE and generated text.
Measuring and Benchmarking Large Language Models’ Capabilities to Generate Persuasive Language
Amalie Brogaard Pauli | Isabelle Augenstein | Ira Assent
Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
Amalie Brogaard Pauli | Isabelle Augenstein | Ira Assent
Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
We are exposed to much information trying to influence us, such as teaser messages, debates, politically framed news, and propaganda — all of which use persuasive language. With the recent interest in Large Language Models (LLMs), we study the ability of LLMs to produce persuasive text. As opposed to prior work which focuses on particular domains or types of persuasion, we conduct a general study across various domains to measure and benchmark to what degree LLMs produce persuasive language - both when explicitly instructed to rewrite text to be more or less persuasive and when only instructed to paraphrase. We construct the new dataset Persuasive-Pairs of pairs of a short text and its rewrite by an LLM to amplify or diminish persuasive language. We multi-annotate the pairs on a relative scale for persuasive language: a valuable resource in itself, and for training a regression model to score and benchmark persuasive language, including for new LLMs across domains. In our analysis, we find that different ‘personas’ in LLaMA3’s system prompt change persuasive language substantially, even when only instructed to paraphrase.
Survey of Cultural Awareness in Language Models: Text and Beyond
Siddhesh Pawar | Junyeong Park | Jiho Jin | Arnav Arora | Junho Myung | Srishti Yadav | Faiz Ghifari Haznitrama | Inhwa Song | Alice Oh | Isabelle Augenstein
Computational Linguistics, Volume 51, Issue 3 - September 2025
Siddhesh Pawar | Junyeong Park | Jiho Jin | Arnav Arora | Junho Myung | Srishti Yadav | Faiz Ghifari Haznitrama | Inhwa Song | Alice Oh | Isabelle Augenstein
Computational Linguistics, Volume 51, Issue 3 - September 2025
Large-scale deployment of large language models (LLMs) in various applications, such as chatbots and virtual assistants, requires LLMs to be culturally sensitive to the user to ensure inclusivity. Culture has been widely studied in psychology and anthropology, and there has been a recent surge in research on making LLMs more culturally inclusive, going beyond multilinguality and building on findings from psychology and anthropology. In this article, we survey efforts towards incorporating cultural awareness into text-based and multimodal LLMs. We start by defining cultural awareness in LLMs, taking definitions of culture from the anthropology and psychology literature as a point of departure. We then examine methodologies adopted for creating cross-cultural datasets, strategies for cultural inclusion in downstream tasks, and methodologies that have been used for benchmarking cultural awareness in LLMs. Further, we discuss the ethical implications of cultural alignment, the role of human–computer interaction in driving cultural inclusion in LLMs, and the role of cultural alignment in driving social science research. We finally provide pointers to future research based on our findings about gaps in the literature.1
Mind the Style Gap: Meta-Evaluation of Style and Attribute Transfer Metrics
Amalie Brogaard Pauli | Isabelle Augenstein | Ira Assent
Findings of the Association for Computational Linguistics: EMNLP 2025
Amalie Brogaard Pauli | Isabelle Augenstein | Ira Assent
Findings of the Association for Computational Linguistics: EMNLP 2025
Large language models (LLMs) make it easy to rewrite a text in any style – e.g. to make it more polite, persuasive, or more positive – but evaluation thereof is not straightforward. A challenge lies in measuring content preservation: that content not attributable to style change is retained. This paper presents a large meta-evaluation of metrics for evaluating style and attribute transfer, focusing on content preservation. We find that meta-evaluation studies on existing datasets lead to misleading conclusions about the suitability of metrics for content preservation. Widely used metrics show a high correlation with human judgments despite being deemed unsuitable for the task – because they do not abstract from style changes when evaluating content preservation. We show that the overly high correlations with human judgment stem from the nature of the test data. To address this issue, we introduce a new, challenging test set specifically designed for evaluating content preservation metrics for style transfer. We construct the data by creating high variation in the content preservation. Using this dataset, we demonstrate that suitable metrics for content preservation for style transfer indeed are style-aware.To support efficient evaluation, we propose a new style-aware method that utilises small language models, obtaining a higher alignment with human judgements than prompting a model of a similar size as an autorater.
Investigating Human Values in Online Communities
Nadav Borenstein | Arnav Arora | Lucie-Aimée Kaffee | Isabelle Augenstein
Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
Nadav Borenstein | Arnav Arora | Lucie-Aimée Kaffee | Isabelle Augenstein
Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
Studying human values is instrumental for cross-cultural research, enabling a better understanding of preferences and behaviour of society at large and communities therein. To study the dynamics of communities online, we propose a method to computationally analyse values present on Reddit. Our method allows analysis at scale, complementing survey based approaches. We train a value relevance and a value polarity classifier, which we thoroughly evaluate using in-domain and out-of-domain human annotations. Using these, we automatically annotate over nine million posts across 12k subreddits with Schwartz values. Our analysis unveils both previously recorded and novel insights into the values prevalent within various online communities. For instance, we discover a very negative stance towards conformity in the Vegan and AbolishTheMonarchy subreddits. Additionally, our study of geographically specific subreddits highlights the correlation between traditional values and conservative U.S. states. Through our work, we demonstrate how our dataset and method can be used as a complementary tool for qualitative study of online communication.
Can Community Notes Replace Professional Fact-Checkers?
Nadav Borenstein | Greta Warren | Desmond Elliott | Isabelle Augenstein
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)
Nadav Borenstein | Greta Warren | Desmond Elliott | Isabelle Augenstein
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)
Two commonly employed strategies to combat the rise of misinformation on social media are (i) fact-checking by professional organisations and (ii) community moderation by platform users. Policy changes by Twitter/X and, more recently, Meta, signal a shift away from partnerships with fact-checking organisations and towards an increased reliance on crowdsourced community notes. However, the extent and nature of dependencies between fact-checking and *helpful* community notes remain unclear. To address these questions, we use language models to annotate a large corpus of Twitter/X community notes with attributes such as topic, cited sources, and whether they refute claims tied to broader misinformation narratives. Our analysis reveals that community notes cite fact-checking sources up to five times more than previously reported. Fact-checking is especially crucial for notes on posts linked to broader narratives, which are *twice* as likely to reference fact-checking sources compared to other sources. Our results show that successful community moderation relies on professional fact-checking and highlight how citizen and professional fact-checking are deeply intertwined.
A Reality Check on Context Utilisation for Retrieval-Augmented Generation
Lovisa Hagström | Sara Vera Marjanovic | Haeun Yu | Arnav Arora | Christina Lioma | Maria Maistro | Pepa Atanasova | Isabelle Augenstein
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Lovisa Hagström | Sara Vera Marjanovic | Haeun Yu | Arnav Arora | Christina Lioma | Maria Maistro | Pepa Atanasova | Isabelle Augenstein
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Retrieval-augmented generation (RAG) helps address the limitations of parametric knowledge embedded within a language model (LM). In real world settings, retrieved information can vary in complexity, yet most investigations of LM utilisation of context has been limited to synthetic text. We introduce DRUID (Dataset of Retrieved Unreliable, Insufficient and Difficult-to-understand contexts) with real-world queries and contexts manually annotated for stance. The dataset is based on the prototypical task of automated claim verification, for which automated retrieval of real-world evidence is crucial. We compare DRUID to synthetic datasets (CounterFact, ConflictQA) and find that artificial datasets often fail to represent the complexity and diversity of realistically retrieved context. We show that synthetic datasets exaggerate context characteristics rare in real retrieved data, which leads to inflated context utilisation results, as measured by our novel ACU score. Moreover, while previous work has mainly focused on singleton context characteristics to explain context utilisation, correlations between singleton context properties and ACU on DRUID are surprisingly small compared to other properties related to context source. Overall, our work underscores the need for real-world aligned context utilisation studies to represent and improve performance in real-world RAG settings.
2024
The Causal Influence of Grammatical Gender on Distributional Semantics
Karolina Stańczak | Kevin Du | Adina Williams | Isabelle Augenstein | Ryan Cotterell
Transactions of the Association for Computational Linguistics, Volume 12
Karolina Stańczak | Kevin Du | Adina Williams | Isabelle Augenstein | Ryan Cotterell
Transactions of the Association for Computational Linguistics, Volume 12
How much meaning influences gender assignment across languages is an active area of research in linguistics and cognitive science. We can view current approaches as aiming to determine where gender assignment falls on a spectrum, from being fully arbitrarily determined to being largely semantically determined. For the latter case, there is a formulation of the neo-Whorfian hypothesis, which claims that even inanimate noun gender influences how people conceive of and talk about objects (using the choice of adjective used to modify inanimate nouns as a proxy for meaning). We offer a novel, causal graphical model that jointly represents the interactions between a noun’s grammatical gender, its meaning, and adjective choice. In accordance with past results, we find a significant relationship between the gender of nouns and the adjectives that modify them. However, when we control for the meaning of the noun, the relationship between grammatical gender and adjective choice is near zero and insignificant.
Can Transformers Learn n-gram Language Models?
Anej Svete | Nadav Borenstein | Mike Zhou | Isabelle Augenstein | Ryan Cotterell
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Anej Svete | Nadav Borenstein | Mike Zhou | Isabelle Augenstein | Ryan Cotterell
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Much theoretical work has described the ability of transformers to represent formal languages. However, linking theoretical results to empirical performance is not straightforward due to the complex interplay between the architecture, the learning algorithm, and training data. To test whether theoretical lower bounds imply learnability of formal languages, we turn to recent work relating transformers to n-gram language models (LMs). We study transformers’ ability to learn random n-gram LMs of two kinds: ones with arbitrary next-symbol probabilities and ones where those are defined with shared parameters. We find that classic estimation techniques for n-gram LMs such as add-𝜆 smoothing outperform transformers on the former, while transformers perform better on the latter, outperforming methods specifically designed to learn n-gram LMs.
Understanding Fine-grained Distortions in Reports of Scientific Findings
Amelie Wuehrl | Dustin Wright | Roman Klinger | Isabelle Augenstein
Findings of the Association for Computational Linguistics: ACL 2024
Amelie Wuehrl | Dustin Wright | Roman Klinger | Isabelle Augenstein
Findings of the Association for Computational Linguistics: ACL 2024
Distorted science communication harms individuals and society as it can lead to unhealthy behavior change and decrease trust in scientific institutions. Given the rapidly increasing volume of science communication in recent years, a fine-grained understanding of how findings from scientific publications are reported to the general public, and methods to detect distortions from the original work automatically, are crucial. Prior work focused on individual aspects of distortions or worked with unpaired data. In this work, we make three foundational contributions towards addressing this problem: (1) annotating 1,600 instances of scientific findings from academic papers paired with corresponding findings as reported in news articles and tweets wrt. four characteristics: causality, certainty, generality and sensationalism; (2) establishing baselines for automatically detecting these characteristics; and (3) analyzing the prevalence of changes in these characteristics in both human-annotated and large-scale unlabeled data. Our results show that scientific findings frequently undergo subtle distortions when reported. Tweets distort findings more often than science news reports. Detecting fine-grained distortions automatically poses a challenging task. In our experiments, fine-tuned task-specific models consistently outperform few-shot LLM prompting.
What Languages are Easy to Language-Model? A Perspective from Learning Probabilistic Regular Languages
Nadav Borenstein | Anej Svete | Robin Chan | Josef Valvoda | Franz Nowak | Isabelle Augenstein | Eleanor Chodroff | Ryan Cotterell
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Nadav Borenstein | Anej Svete | Robin Chan | Josef Valvoda | Franz Nowak | Isabelle Augenstein | Eleanor Chodroff | Ryan Cotterell
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
What can large language models learn? By definition, language models (LM) are distributionsover strings. Therefore, an intuitive way of addressing the above question is to formalize it as a matter of learnability of classes of distributions over strings. While prior work in this direction focused on assessing the theoretical limits, in contrast, we seek to understand the empirical learnability. Unlike prior empirical work, we evaluate neural LMs on their home turf—learning probabilistic languages—rather than as classifiers of formal languages. In particular, we investigate the learnability of regular LMs (RLMs) by RNN and Transformer LMs. We empirically test the learnability of RLMs as a function of various complexity parameters of the RLM and the hidden state size of the neural LM. We find that the RLM rank, which corresponds to the size of linear space spanned by the logits of its conditional distributions, and the expected length of sampled strings are strong and significant predictors of learnability for both RNNs and Transformers. Several other predictors also reach significance, but with differing patterns between RNNs and Transformers.
Revealing the Parametric Knowledge of Language Models: A Unified Framework for Attribution Methods
Haeun Yu | Pepa Atanasova | Isabelle Augenstein
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Haeun Yu | Pepa Atanasova | Isabelle Augenstein
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Language Models (LMs) acquire parametric knowledge from their training process, embedding it within their weights. The increasing scalability of LMs, however, poses significant challenges for understanding a model’s inner workings and further for updating or correcting this embedded knowledge without the significant cost of retraining. This underscores the importance of unveiling exactly what knowledge is stored and its association with specific model components. Instance Attribution (IA) and Neuron Attribution (NA) offer insights into this training-acquired knowledge, though they have not been compared systematically. Our study introduces a novel evaluation framework to quantify and compare the knowledge revealed by IA and NA. To align the results of the methods we introduce the attribution method NA-Instances to apply NA for retrieving influential training instances, and IA-Neurons to discover important neurons of influential instances discovered by IA. We further propose a comprehensive list of faithfulness tests to evaluate the comprehensiveness and sufficiency of the explanations provided by both methods. Through extensive experiments and analysis, we demonstrate that NA generally reveals more diverse and comprehensive information regarding the LM’s parametric knowledge compared to IA. Nevertheless, IA provides unique and valuable insights into the LM’s parametric knowledge, which are not revealed by NA. Our findings further suggest the potential of a synergistic approach of combining the diverse findings of IA and NA for a more holistic understanding of an LM’s parametric knowledge.
Semantic Sensitivities and Inconsistent Predictions: Measuring the Fragility of NLI Models
Erik Arakelyan | Zhaoqi Liu | Isabelle Augenstein
Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers)
Erik Arakelyan | Zhaoqi Liu | Isabelle Augenstein
Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers)
Recent studies of the emergent capabilities of transformer-based Natural Language Understanding (NLU) models have indicated that they have an understanding of lexical and compositional semantics. We provide evidence that suggests these claims should be taken with a grain of salt: we find that state-of-the-art Natural Language Inference (NLI) models are sensitive towards minor semantics preserving surface-form variations, which lead to sizable inconsistent model decisions during inference. Notably, this behaviour differs from valid and in-depth comprehension of compositional semantics, however does neither emerge when evaluating model accuracy on standard benchmarks nor when probing for syntactic, monotonic, and logically robust reasoning. We propose a novel framework to measure the extent of semantic sensitivity. To this end, we evaluate NLI models on adversarially generated examples containing minor semantics-preserving surface-form input noise. This is achieved using conditional text generation, with the explicit condition that the NLI model predicts the relationship between the original and adversarial inputs as a symmetric equivalence entailment. We systematically study the effects of the phenomenon across NLI models for in- and out-of- domain settings. Our experiments show that semantic sensitivity causes performance degradations of 12.92% and 23.71% average over in- and out-of- domain settings, respectively. We further perform ablation studies, analysing this phenomenon across models, datasets, and variations in inference and show that semantic sensitivity can lead to major inconsistency within model predictions.
LLM Tropes: Revealing Fine-Grained Values and Opinions in Large Language Models
Dustin Wright | Arnav Arora | Nadav Borenstein | Srishti Yadav | Serge Belongie | Isabelle Augenstein
Findings of the Association for Computational Linguistics: EMNLP 2024
Dustin Wright | Arnav Arora | Nadav Borenstein | Srishti Yadav | Serge Belongie | Isabelle Augenstein
Findings of the Association for Computational Linguistics: EMNLP 2024
Uncovering latent values and opinions embedded in large language models (LLMs) can help identify biases and mitigate potential harm. Recently, this has been approached by prompting LLMs with survey questions and quantifying the stances in the outputs towards morally and politically charged statements. However, the stances generated by LLMs can vary greatly depending on how they are prompted, and there are many ways to argue for or against a given position. In this work, we propose to address this by analysing a large and robust dataset of 156k LLM responses to the 62 propositions of the Political Compass Test (PCT) generated by 6 LLMs using 420 prompt variations. We perform coarse-grained analysis of their generated stances and fine-grained analysis of the plain text justifications for those stances. For fine-grained analysis, we propose to identify tropes in the responses: semantically similar phrases that are recurrent and consistent across different prompts, revealing natural patterns in the text that a given LLM is prone to produce. We find that demographic features added to prompts significantly affect outcomes on the PCT, reflecting bias, as well as disparities between the results of tests when eliciting closed-form vs. open domain responses. Additionally, patterns in the plain text rationales via tropes show that similar justifications are repeatedly generated across models and prompts even with disparate stances.
Investigating the Impact of Model Instability on Explanations and Uncertainty
Sara Vera Marjanović | Isabelle Augenstein | Christina Lioma
Findings of the Association for Computational Linguistics: ACL 2024
Sara Vera Marjanović | Isabelle Augenstein | Christina Lioma
Findings of the Association for Computational Linguistics: ACL 2024
Explainable AI methods facilitate the understanding of model behaviour, yet, small, imperceptible perturbations to inputs can vastly distort explanations. As these explanations are typically evaluated holistically, before model deployment, it is difficult to assess when a particular explanation is trustworthy. Some studies have tried to create confidence estimators for explanations, but none have investigated an existing link between uncertainty and explanation quality. We artificially simulate epistemic uncertainty in text input by introducing noise at inference time. In this large-scale empirical study, we insert different levels of noise perturbations and measure the effect on the output of pre-trained language models and different uncertainty metrics. Realistic perturbations have minimal effect on performance and explanations, yet masking has a drastic effect. We find that high uncertainty doesn’t necessarily imply low explanation plausibility; the correlation between the two metrics can be moderately positive when noise is exposed during the training process. This suggests that noise-augmented models may be better at identifying salient tokens when uncertain. Furthermore, when predictive and epistemic uncertainty measures are over-confident, the robustness of a saliency map to perturbation can indicate model stability issues. Integrated Gradients shows the overall greatest robustness to perturbation, while still showing model-specific patterns in performance; however, this phenomenon is limited to smaller Transformer-based language models.
DYNAMICQA: Tracing Internal Knowledge Conflicts in Language Models
Sara Vera Marjanovic | Haeun Yu | Pepa Atanasova | Maria Maistro | Christina Lioma | Isabelle Augenstein
Findings of the Association for Computational Linguistics: EMNLP 2024
Sara Vera Marjanovic | Haeun Yu | Pepa Atanasova | Maria Maistro | Christina Lioma | Isabelle Augenstein
Findings of the Association for Computational Linguistics: EMNLP 2024
Knowledge-intensive language understanding tasks require Language Models (LMs) to integrate relevant context, mitigating their inherent weaknesses, such as incomplete or outdated knowledge. However, conflicting knowledge can be present in the LM’s parameters, termed intra-memory conflict, which can affect a model’s propensity to accept contextual knowledge. To study the effect of intra-memory conflict on LM’s ability to accept the relevant context, we utilise two knowledge conflict measures and a novel dataset containing inherently conflicting data, DYNAMICQA. This dataset includes facts with a temporal dynamic nature where facts can change over time and disputable dynamic facts, which can change depending on the viewpoint. DYNAMICQA is the first to include real-world knowledge conflicts and provide context to study the link between the different types of knowledge conflicts. We also evaluate several measures on their ability to reflect the presence of intra-memory conflict: semantic entropy and a novel coherent persuasion score. With our extensive experiments, we verify that LMs show a greater degree of intra-memory conflict with dynamic facts compared to facts that have a single truth value. Further, we reveal that facts with intra-memory conflict are harder to update with context, suggesting that retrieval-augmented generation will struggle with the most commonly adapted facts
Factcheck-Bench: Fine-Grained Evaluation Benchmark for Automatic Fact-checkers
Yuxia Wang | Revanth Gangi Reddy | Zain Muhammad Mujahid | Arnav Arora | Aleksandr Rubashevskii | Jiahui Geng | Osama Mohammed Afzal | Liangming Pan | Nadav Borenstein | Aditya Pillai | Isabelle Augenstein | Iryna Gurevych | Preslav Nakov
Findings of the Association for Computational Linguistics: EMNLP 2024
Yuxia Wang | Revanth Gangi Reddy | Zain Muhammad Mujahid | Arnav Arora | Aleksandr Rubashevskii | Jiahui Geng | Osama Mohammed Afzal | Liangming Pan | Nadav Borenstein | Aditya Pillai | Isabelle Augenstein | Iryna Gurevych | Preslav Nakov
Findings of the Association for Computational Linguistics: EMNLP 2024
The increased use of large language models (LLMs) across a variety of real-world applications calls for mechanisms to verify the factual accuracy of their outputs. In this work, we present Factcheck-Bench, a holistic end-to-end framework for annotating and evaluating the factuality of LLM-generated responses, which encompasses a multi-stage annotation scheme designed to yield detailed labels for fact-checking and correcting not just the final prediction, but also the intermediate steps that a fact-checking system might need to take. Based on this framework, we construct an open-domain factuality benchmark in three-levels of granularity: claim, sentence, and document. We further propose a system, Factcheck-GPT, which follows our framework, and we show that it outperforms several popular LLM fact-checkers. We make our annotation tool, annotated data, benchmark, and code available at https://github.com/yuxiaw/Factcheck-GPT.
Social Bias Probing: Fairness Benchmarking for Language Models
Marta Marchiori Manerba | Karolina Stanczak | Riccardo Guidotti | Isabelle Augenstein
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Marta Marchiori Manerba | Karolina Stanczak | Riccardo Guidotti | Isabelle Augenstein
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
While the impact of social biases in language models has been recognized, prior methods for bias evaluation have been limited to binary association tests on small datasets, limiting our understanding of bias complexities. This paper proposes a novel framework for probing language models for social biases by assessing disparate treatment, which involves treating individuals differently according to their affiliation with a sensitive demographic group. We curate SoFa, a large-scale benchmark designed to address the limitations of existing fairness collections. SoFa expands the analysis beyond the binary comparison of stereotypical versus anti-stereotypical identities to include a diverse range of identities and stereotypes. Comparing our methodology with existing benchmarks, we reveal that biases within language models are more nuanced than acknowledged, indicating a broader scope of encoded biases than previously recognized. Benchmarking LMs on SoFa, we expose how identities expressing different religions lead to the most pronounced disparate treatments across all models. Finally, our findings indicate that real-life adversities faced by various groups such as women and people with disabilities are mirrored in the behavior of these models.
2023
PHD: Pixel-Based Language Modeling of Historical Documents
Nadav Borenstein | Phillip Rust | Desmond Elliott | Isabelle Augenstein
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Nadav Borenstein | Phillip Rust | Desmond Elliott | Isabelle Augenstein
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
The digitisation of historical documents has provided historians with unprecedented research opportunities. Yet, the conventional approach to analysing historical documents involves converting them from images to text using OCR, a process that overlooks the potential benefits of treating them as images and introduces high levels of noise. To bridge this gap, we take advantage of recent advancements in pixel-based language models trained to reconstruct masked patches of pixels instead of predicting token distributions. Due to the scarcity of real historical scans, we propose a novel method for generating synthetic scans to resemble real historical documents. We then pre-train our model, PHD, on a combination of synthetic scans and real historical newspapers from the 1700-1900 period. Through our experiments, we demonstrate that PHD exhibits high proficiency in reconstructing masked image patches and provide evidence of our model’s noteworthy language understanding capabilities. Notably, we successfully apply our model to a historical QA task, highlighting its usefulness in this domain.
Proceedings of the 8th Workshop on Representation Learning for NLP (RepL4NLP 2023)
Burcu Can | Maximilian Mozes | Samuel Cahyawijaya | Naomi Saphra | Nora Kassner | Shauli Ravfogel | Abhilasha Ravichander | Chen Zhao | Isabelle Augenstein | Anna Rogers | Kyunghyun Cho | Edward Grefenstette | Lena Voita
Proceedings of the 8th Workshop on Representation Learning for NLP (RepL4NLP 2023)
Burcu Can | Maximilian Mozes | Samuel Cahyawijaya | Naomi Saphra | Nora Kassner | Shauli Ravfogel | Abhilasha Ravichander | Chen Zhao | Isabelle Augenstein | Anna Rogers | Kyunghyun Cho | Edward Grefenstette | Lena Voita
Proceedings of the 8th Workshop on Representation Learning for NLP (RepL4NLP 2023)
Explaining Interactions Between Text Spans
Sagnik Ray Choudhury | Pepa Atanasova | Isabelle Augenstein
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Sagnik Ray Choudhury | Pepa Atanasova | Isabelle Augenstein
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Reasoning over spans of tokens from different parts of the input is essential for natural language understanding (NLU) tasks such as fact-checking (FC), machine reading comprehension (MRC) or natural language inference (NLI). However, existing highlight-based explanations primarily focus on identifying individual important features or interactions only between adjacent tokens or tuples of tokens. Most notably, there is a lack of annotations capturing the human decision-making process with respect to the necessary interactions for informed decision-making in such tasks. To bridge this gap, we introduce SpanEx, a multi-annotator dataset of human span interaction explanations for two NLU tasks: NLI and FC. We then investigate the decision-making processes of multiple fine-tuned large language models in terms of the employed connections between spans in separate parts of the input and compare them to the human reasoning processes. Finally, we present a novel community detection based unsupervised method to extract such interaction explanations. We make the code and the dataset available on [Github](https://github.com/copenlu/spanex). The dataset is also available on [Huggingface datasets](https://huggingface.co/datasets/copenlu/spanex).
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics
Andreas Vlachos | Isabelle Augenstein
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics
Andreas Vlachos | Isabelle Augenstein
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics
Why Should This Article Be Deleted? Transparent Stance Detection in Multilingual Wikipedia Editor Discussions
Lucie-Aimée Kaffee | Arnav Arora | Isabelle Augenstein
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Lucie-Aimée Kaffee | Arnav Arora | Isabelle Augenstein
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
The moderation of content on online platforms is usually non-transparent. On Wikipedia, however, this discussion is carried out publicly and editors are encouraged to use the content moderation policies as explanations for making moderation decisions. Currently, only a few comments explicitly mention those policies – 20% of the English ones, but as few as 2% of the German and Turkish comments. To aid in this process of understanding how content is moderated, we construct a novel multilingual dataset of Wikipedia editor discussions along with their reasoning in three languages. The dataset contains the stances of the editors (keep, delete, merge, comment), along with the stated reason, and a content moderation policy, for each edit decision. We demonstrate that stance and corresponding reason (policy) can be predicted jointly with a high degree of accuracy, adding transparency to the decision-making process. We release both our joint prediction models and the multilingual content moderation dataset for further research on automated transparent content moderation.
Measuring Intersectional Biases in Historical Documents
Nadav Borenstein | Karolina Stanczak | Thea Rolskov | Natacha Klein Käfer | Natália da Silva Perez | Isabelle Augenstein
Findings of the Association for Computational Linguistics: ACL 2023
Nadav Borenstein | Karolina Stanczak | Thea Rolskov | Natacha Klein Käfer | Natália da Silva Perez | Isabelle Augenstein
Findings of the Association for Computational Linguistics: ACL 2023
Data-driven analyses of biases in historical texts can help illuminate the origin and development of biases prevailing in modern society. However, digitised historical documents pose a challenge for NLP practitioners as these corpora suffer from errors introduced by optical character recognition (OCR) and are written in an archaic language. In this paper, we investigate the continuities and transformations of bias in historical newspapers published in the Caribbean during the colonial era (18th to 19th centuries). Our analyses are performed along the axes of gender, race, and their intersection. We examine these biases by conducting a temporal study in which we measure the development of lexical associations using distributional semantics models and word embeddings. Further, we evaluate the effectiveness of techniques designed to process OCR-generated data and assess their stability when trained on and applied to the noisy historical newspapers. We find that there is a trade-off between the stability of the word embeddings and their compatibility with the historical dataset. We provide evidence that gender and racial biases are interdependent, and their intersection triggers distinct effects. These findings align with the theory of intersectionality, which stresses that biases affecting people with multiple marginalised identities compound to more than the sum of their constituents.
People Make Better Edits: Measuring the Efficacy of LLM-Generated Counterfactually Augmented Data for Harmful Language Detection
Indira Sen | Dennis Assenmacher | Mattia Samory | Isabelle Augenstein | Wil Aalst | Claudia Wagner
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Indira Sen | Dennis Assenmacher | Mattia Samory | Isabelle Augenstein | Wil Aalst | Claudia Wagner
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
NLP models are used in a variety of critical social computing tasks, such as detecting sexist, racist, or otherwise hateful content. Therefore, it is imperative that these models are robust to spurious features. Past work has attempted to tackle such spurious features using training data augmentation, including Counterfactually Augmented Data (CADs). CADs introduce minimal changes to existing training data points and flip their labels; training on them may reduce model dependency on spurious features. However, manually generating CADs can be time-consuming and expensive. Hence in this work, we assess if this task can be automated using generative NLP models. We automatically generate CADs using Polyjuice, ChatGPT, and Flan-T5, and evaluate their usefulness in improving model robustness compared to manually-generated CADs. By testing both model performance on multiple out-of-domain test sets and individual data point efficacy, our results show that while manual CADs are still the most effective, CADs generated by ChatGPT come a close second. One key reason for the lower performance of automated methods is that the changes they introduce are often insufficient to flip the original label.
Findings of the Association for Computational Linguistics: EACL 2023
Andreas Vlachos | Isabelle Augenstein
Findings of the Association for Computational Linguistics: EACL 2023
Andreas Vlachos | Isabelle Augenstein
Findings of the Association for Computational Linguistics: EACL 2023
Multilingual Event Extraction from Historical Newspaper Adverts
Nadav Borenstein | Natália da Silva Perez | Isabelle Augenstein
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Nadav Borenstein | Natália da Silva Perez | Isabelle Augenstein
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
NLP methods can aid historians in analyzing textual materials in greater volumes than manually feasible. Developing such methods poses substantial challenges though. First, acquiring large, annotated historical datasets is difficult, as only domain experts can reliably label them. Second, most available off-the-shelf NLP models are trained on modern language texts, rendering them significantly less effective when applied to historical corpora. This is particularly problematic for less well studied tasks, and for languages other than English. This paper addresses these challenges while focusing on the under-explored task of event extraction from a novel domain of historical texts. We introduce a new multilingual dataset in English, French, and Dutch composed of newspaper ads from the early modern colonial period reporting on enslaved people who liberated themselves from enslavement. We find that: 1) even with scarce annotated data, it is possible to achieve surprisingly good results by formulating the problem as an extractive QA task and leveraging existing datasets and models for modern languages; and 2) cross-lingual low-resource learning for historical languages is highly challenging, and machine translation of the historical datasets to the considered target languages is, in practice, often the best-performing solution.
Probing Pre-Trained Language Models for Cross-Cultural Differences in Values
Arnav Arora | Lucie-aimée Kaffee | Isabelle Augenstein
Proceedings of the First Workshop on Cross-Cultural Considerations in NLP (C3NLP)
Arnav Arora | Lucie-aimée Kaffee | Isabelle Augenstein
Proceedings of the First Workshop on Cross-Cultural Considerations in NLP (C3NLP)
Language embeds information about social, cultural, and political values people hold. Prior work has explored potentially harmful social biases encoded in Pre-trained Language Models (PLMs). However, there has been no systematic study investigating how values embedded in these models vary across cultures. In this paper, we introduce probes to study which cross-cultural values are embedded in these models, and whether they align with existing theories and cross-cultural values surveys. We find that PLMs capture differences in values across cultures, but those only weakly align with established values surveys. We discuss implications of using mis-aligned models in cross-cultural settings, as well as ways of aligning PLMs with values surveys.
Topic-Guided Sampling For Data-Efficient Multi-Domain Stance Detection
Erik Arakelyan | Arnav Arora | Isabelle Augenstein
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Erik Arakelyan | Arnav Arora | Isabelle Augenstein
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
The task of Stance Detection is concerned with identifying the attitudes expressed by an author towards a target of interest. This task spans a variety of domains ranging from social media opinion identification to detecting the stance for a legal claim. However, the framing of the task varies within these domains in terms of the data collection protocol, the label dictionary and the number of available annotations. Furthermore, these stance annotations are significantly imbalanced on a per-topic and inter-topic basis. These make multi-domain stance detection challenging, requiring standardization and domain adaptation. To overcome this challenge, we propose Topic Efficient StancE Detection (TESTED), consisting of a topic-guided diversity sampling technique used for creating a multi-domain data efficient training set and a contrastive objective that is used for fine-tuning a stance classifier using the produced set. We evaluate the method on an existing benchmark of 16 datasets with in-domain, i.e. all topics seen and out-of-domain, i.e. unseen topics, experiments. The results show that the method outperforms the state-of-the-art with an average of 3.5 F1 points increase in-domain and is more generalizable with an averaged 10.2 F1 on out-of-domain evaluation while using <10% of the training data. We show that our sampling technique mitigates both inter- and per-topic class imbalances. Finally, our analysis demonstrates that the contrastive learning objective allows the model for a more pronounced segmentation of samples with varying labels.
Thorny Roses: Investigating the Dual Use Dilemma in Natural Language Processing
Lucie-Aimée Kaffee | Arnav Arora | Zeerak Talat | Isabelle Augenstein
Findings of the Association for Computational Linguistics: EMNLP 2023
Lucie-Aimée Kaffee | Arnav Arora | Zeerak Talat | Isabelle Augenstein
Findings of the Association for Computational Linguistics: EMNLP 2023
Dual use, the intentional, harmful reuse of technology and scientific artefacts, is an ill-defined problem within the context of Natural Language Processing (NLP). As large language models (LLMs) have advanced in their capabilities and become more accessible, the risk of their intentional misuse becomes more prevalent. To prevent such intentional malicious use, it is necessary for NLP researchers and practitioners to understand and mitigate the risks of their research. Hence, we present an NLP-specific definition of dual use informed by researchers and practitioners in the field. Further, we propose a checklist focusing on dual-use in NLP, that can be integrated into existing conference ethics-frameworks. The definition and checklist are created based on a survey of NLP researchers and practitioners.
Measuring Gender Bias in West Slavic Language Models
Sandra Martinková | Karolina Stanczak | Isabelle Augenstein
Proceedings of the 9th Workshop on Slavic Natural Language Processing 2023 (SlavicNLP 2023)
Sandra Martinková | Karolina Stanczak | Isabelle Augenstein
Proceedings of the 9th Workshop on Slavic Natural Language Processing 2023 (SlavicNLP 2023)
Pre-trained language models have been known to perpetuate biases from the underlying datasets to downstream tasks. However, these findings are predominantly based on monolingual language models for English, whereas there are few investigative studies of biases encoded in language models for languages beyond English. In this paper, we fill this gap by analysing gender bias in West Slavic language models. We introduce the first template-based dataset in Czech, Polish, and Slovak for measuring gender bias towards male, female and non-binary subjects. We complete the sentences using both mono- and multilingual language models and assess their suitability for the masked language modelling objective. Next, we measure gender bias encoded in West Slavic language models by quantifying the toxicity and genderness of the generated words. We find that these language models produce hurtful completions that depend on the subject’s gender. Perhaps surprisingly, Czech, Slovak, and Polish language models produce more hurtful completions with men as subjects, which, upon inspection, we find is due to completions being related to violence, death, and sickness.
Faithfulness Tests for Natural Language Explanations
Pepa Atanasova | Oana-Maria Camburu | Christina Lioma | Thomas Lukasiewicz | Jakob Grue Simonsen | Isabelle Augenstein
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)
Pepa Atanasova | Oana-Maria Camburu | Christina Lioma | Thomas Lukasiewicz | Jakob Grue Simonsen | Isabelle Augenstein
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)
Explanations of neural models aim to reveal a model’s decision-making process for its predictions. However, recent work shows that current methods giving explanations such as saliency maps or counterfactuals can be misleading, as they are prone to present reasons that are unfaithful to the model’s inner workings. This work explores the challenging question of evaluating the faithfulness of natural language explanations (NLEs). To this end, we present two tests. First, we propose a counterfactual input editor for inserting reasons that lead to counterfactual predictions but are not reflected by the NLEs. Second, we reconstruct inputs from the reasons stated in the generated NLEs and check how often they lead to the same predictions. Our tests can evaluate emerging NLE models, proving a fundamental tool in the development of faithful NLEs.
2022
Multi3Generation: Multitask, Multilingual, Multimodal Language Generation
Anabela Barreiro | José GC de Souza | Albert Gatt | Mehul Bhatt | Elena Lloret | Aykut Erdem | Dimitra Gkatzia | Helena Moniz | Irene Russo | Fabio Kepler | Iacer Calixto | Marcin Paprzycki | François Portet | Isabelle Augenstein | Mirela Alhasani
Proceedings of the 23rd Annual Conference of the European Association for Machine Translation
Anabela Barreiro | José GC de Souza | Albert Gatt | Mehul Bhatt | Elena Lloret | Aykut Erdem | Dimitra Gkatzia | Helena Moniz | Irene Russo | Fabio Kepler | Iacer Calixto | Marcin Paprzycki | François Portet | Isabelle Augenstein | Mirela Alhasani
Proceedings of the 23rd Annual Conference of the European Association for Machine Translation
This paper presents the Multitask, Multilingual, Multimodal Language Generation COST Action – Multi3Generation (CA18231), an interdisciplinary network of research groups working on different aspects of language generation. This “meta-paper” will serve as reference for citations of the Action in future publications. It presents the objectives, challenges and a the links for the achieved outcomes.
Same Neurons, Different Languages: Probing Morphosyntax in Multilingual Pre-trained Models
Karolina Stanczak | Edoardo Ponti | Lucas Torroba Hennigen | Ryan Cotterell | Isabelle Augenstein
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies
Karolina Stanczak | Edoardo Ponti | Lucas Torroba Hennigen | Ryan Cotterell | Isabelle Augenstein
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies
The success of multilingual pre-trained models is underpinned by their ability to learn representations shared by multiple languages even in absence of any explicit supervision. However, it remains unclear how these models learn to generalise across languages. In this work, we conjecture that multilingual pre-trained models can derive language-universal abstractions about grammar. In particular, we investigate whether morphosyntactic information is encoded in the same subset of neurons in different languages. We conduct the first large-scale empirical study over 43 languages and 14 morphosyntactic categories with a state-of-the-art neuron-level probe. Our findings show that the cross-lingual overlap between neurons is significant, but its extent may vary across categories and depends on language proximity and pre-training data size.
Neighborhood Contrastive Learning for Scientific Document Representations with Citation Embeddings
Malte Ostendorff | Nils Rethmeier | Isabelle Augenstein | Bela Gipp | Georg Rehm
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing
Malte Ostendorff | Nils Rethmeier | Isabelle Augenstein | Bela Gipp | Georg Rehm
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing
Learning scientific document representations can be substantially improved through contrastive learning objectives, where the challenge lies in creating positive and negative training samples that encode the desired similarity semantics. Prior work relies on discrete citation relations to generate contrast samples. However, discrete citations enforce a hard cut-off to similarity. This is counter-intuitive to similarity-based learning and ignores that scientific papers can be very similar despite lacking a direct citation - a core problem of finding related research. Instead, we use controlled nearest neighbor sampling over citation graph embeddings for contrastive learning. This control allows us to learn continuous similarity, to sample hard-to-learn negatives and positives, and also to avoid collisions between negative and positive samples by controlling the sampling margin between them. The resulting method SciNCL outperforms the state-of-the-art on the SciDocs benchmark. Furthermore, we demonstrate that it can train (or tune) language models sample-efficiently and that it can be combined with recent training-efficient methods. Perhaps surprisingly, even training a general-domain language model this way outperforms baselines pretrained in-domain.
Fact Checking with Insufficient Evidence
Pepa Atanasova | Jakob Grue Simonsen | Christina Lioma | Isabelle Augenstein
Transactions of the Association for Computational Linguistics, Volume 10
Pepa Atanasova | Jakob Grue Simonsen | Christina Lioma | Isabelle Augenstein
Transactions of the Association for Computational Linguistics, Volume 10
Automating the fact checking (FC) process relies on information obtained from external sources. In this work, we posit that it is crucial for FC models to make veracity predictions only when there is sufficient evidence and otherwise indicate when it is not enough. To this end, we are the first to study what information FC models consider sufficient by introducing a novel task and advancing it with three main contributions. First, we conduct an in-depth empirical analysis of the task with a new fluency-preserving method for omitting information from the evidence at the constituent and sentence level. We identify when models consider the remaining evidence (in)sufficient for FC, based on three trained models with different Transformer architectures and three FC datasets. Second, we ask annotators whether the omitted evidence was important for FC, resulting in a novel diagnostic dataset, SufficientFacts1, for FC with omitted evidence. We find that models are least successful in detecting missing evidence when adverbial modifiers are omitted (21% accuracy), whereas it is easiest for omitted date modifiers (63% accuracy). Finally, we propose a novel data augmentation strategy for contrastive self-learning of missing evidence by employing the proposed omission method combined with tri-training. It improves performance for Evidence Sufficiency Prediction by up to 17.8 F1 score, which in turn improves FC performance by up to 2.6 F1 score.
A Survey on Stance Detection for Mis- and Disinformation Identification
Momchil Hardalov | Arnav Arora | Preslav Nakov | Isabelle Augenstein
Findings of the Association for Computational Linguistics: NAACL 2022
Momchil Hardalov | Arnav Arora | Preslav Nakov | Isabelle Augenstein
Findings of the Association for Computational Linguistics: NAACL 2022
Understanding attitudes expressed in texts, also known as stance detection, plays an important role in systems for detecting false information online, be it misinformation (unintentionally false) or disinformation (intentionally false information). Stance detection has been framed in different ways, including (a) as a component of fact-checking, rumour detection, and detecting previously fact-checked claims, or (b) as a task in its own right. While there have been prior efforts to contrast stance detection with other related tasks such as argumentation mining and sentiment analysis, there is no existing survey on examining the relationship between stance detection and mis- and disinformation detection. Here, we aim to bridge this gap by reviewing and analysing existing work in this area, with mis- and disinformation in focus, and discussing lessons learnt and future challenges.
Generating Scientific Claims for Zero-Shot Scientific Fact Checking
Dustin Wright | David Wadden | Kyle Lo | Bailey Kuehl | Arman Cohan | Isabelle Augenstein | Lucy Lu Wang
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Dustin Wright | David Wadden | Kyle Lo | Bailey Kuehl | Arman Cohan | Isabelle Augenstein | Lucy Lu Wang
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Automated scientific fact checking is difficult due to the complexity of scientific language and a lack of significant amounts of training data, as annotation requires domain expertise. To address this challenge, we propose scientific claim generation, the task of generating one or more atomic and verifiable claims from scientific sentences, and demonstrate its usefulness in zero-shot fact checking for biomedical claims. We propose CLAIMGEN-BART, a new supervised method for generating claims supported by the literature, as well as KBIN, a novel method for generating claim negations. Additionally, we adapt an existing unsupervised entity-centric method of claim generation to biomedical claims, which we call CLAIMGEN-ENTITY. Experiments on zero-shot fact checking demonstrate that both CLAIMGEN-ENTITY and CLAIMGEN-BART, coupled with KBIN, achieve up to 90% performance of fully supervised models trained on manually annotated claims and evidence. A rigorous evaluation study demonstrates significant improvement in generated claim and negation quality over existing baselines
Machine Reading, Fast and Slow: When Do Models “Understand” Language?
Sagnik Ray Choudhury | Anna Rogers | Isabelle Augenstein
Proceedings of the 29th International Conference on Computational Linguistics
Sagnik Ray Choudhury | Anna Rogers | Isabelle Augenstein
Proceedings of the 29th International Conference on Computational Linguistics
Two of the most fundamental issues in Natural Language Understanding (NLU) at present are: (a) how it can established whether deep learning-based models score highly on NLU benchmarks for the ”right” reasons; and (b) what those reasons would even be. We investigate the behavior of reading comprehension models with respect to two linguistic ”skills”: coreference resolution and comparison. We propose a definition for the reasoning steps expected from a system that would be ”reading slowly”, and compare that with the behavior of five models of the BERT family of various sizes, observed through saliency scores and counterfactual explanations. We find that for comparison (but not coreference) the systems based on larger encoders are more likely to rely on the ”right” information, but even they struggle with generalization, suggesting that they still learn specific lexical patterns rather than the general principles of comparison.
Multi-sense Language Modelling
Andrea Lekkas | Peter Schneider-Kamp | Isabelle Augenstein
Proceedings of the Workshop on Dimensions of Meaning: Distributional and Curated Semantics (DistCurate 2022)
Andrea Lekkas | Peter Schneider-Kamp | Isabelle Augenstein
Proceedings of the Workshop on Dimensions of Meaning: Distributional and Curated Semantics (DistCurate 2022)
The effectiveness of a language model is influenced by its token representations, which must encode contextual information and handle the same word form having a plurality of meanings (polysemy). Currently, none of the common language modelling architectures explicitly model polysemy. We propose a language model which not only predicts the next word, but also its sense in context. We argue that this higher prediction granularity may be useful for end tasks such as assistive writing, and allow for more a precise linking of language models with knowledge bases. We find that multi-sense language modelling requires architectures that go beyond standard language models, and here propose a localized prediction framework that decomposes the task into a word followed by a sense prediction task. To aid sense prediction, we utilise a Graph Attention Network, which encodes definitions and example uses of word senses. Overall, we find that multi-sense language modelling is a highly challenging task, and suggest that future work focus on the creation of more annotated training datasets.
Counterfactually Augmented Data and Unintended Bias: The Case of Sexism and Hate Speech Detection
Indira Sen | Mattia Samory | Claudia Wagner | Isabelle Augenstein
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies
Indira Sen | Mattia Samory | Claudia Wagner | Isabelle Augenstein
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies
Counterfactually Augmented Data (CAD) aims to improve out-of-domain generalizability, an indicator of model robustness. The improvement is credited to promoting core features of the construct over spurious artifacts that happen to correlate with it. Yet, over-relying on core features may lead to unintended model bias. Especially, construct-driven CAD—perturbations of core features—may induce models to ignore the context in which core features are used. Here, we test models for sexism and hate speech detection on challenging data: non-hate and non-sexist usage of identity and gendered terms. On these hard cases, models trained on CAD, especially construct-driven CAD, show higher false positive rates than models trained on the original, unperturbed data. Using a diverse set of CAD—construct-driven and construct-agnostic—reduces such unintended bias.
Can Edge Probing Tests Reveal Linguistic Knowledge in QA Models?
Sagnik Ray Choudhury | Nikita Bhutani | Isabelle Augenstein
Proceedings of the 29th International Conference on Computational Linguistics
Sagnik Ray Choudhury | Nikita Bhutani | Isabelle Augenstein
Proceedings of the 29th International Conference on Computational Linguistics
There have been many efforts to try to understand what grammatical knowledge (e.g., ability to understand the part of speech of a token) is encoded in large pre-trained language models (LM). This is done through ‘Edge Probing’ (EP) tests: supervised classification tasks to predict the grammatical properties of a span (whether it has a particular part of speech) using only the token representations coming from the LM encoder. However, most NLP applications fine-tune these LM encoders for specific tasks. Here, we ask: if an LM is fine-tuned, does the encoding of linguistic information in it change, as measured by EP tests? Specifically, we focus on the task of Question Answering (QA) and conduct experiments on multiple datasets. We find that EP test results do not change significantly when the fine-tuned model performs well or in adversarial situations where the model is forced to learn wrong correlations. From a similar finding, some recent papers conclude that fine-tuning does not change linguistic knowledge in encoders but they do not provide an explanation. We find that EP models are susceptible to exploiting spurious correlations in the EP datasets. When this dataset bias is corrected, we do see an improvement in the EP test results as expected.
Proceedings of the 7th Workshop on Representation Learning for NLP
Spandana Gella | He He | Bodhisattwa Prasad Majumder | Burcu Can | Eleonora Giunchiglia | Samuel Cahyawijaya | Sewon Min | Maximilian Mozes | Xiang Lorraine Li | Isabelle Augenstein | Anna Rogers | Kyunghyun Cho | Edward Grefenstette | Laura Rimell | Chris Dyer
Proceedings of the 7th Workshop on Representation Learning for NLP
Spandana Gella | He He | Bodhisattwa Prasad Majumder | Burcu Can | Eleonora Giunchiglia | Samuel Cahyawijaya | Sewon Min | Maximilian Mozes | Xiang Lorraine Li | Isabelle Augenstein | Anna Rogers | Kyunghyun Cho | Edward Grefenstette | Laura Rimell | Chris Dyer
Proceedings of the 7th Workshop on Representation Learning for NLP
Modeling Information Change in Science Communication with Semantically Matched Paraphrases
Dustin Wright | Jiaxin Pei | David Jurgens | Isabelle Augenstein
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing
Dustin Wright | Jiaxin Pei | David Jurgens | Isabelle Augenstein
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing
Whether the media faithfully communicate scientific information has long been a core issue to the science community. Automatically identifying paraphrased scientific findings could enable large-scale tracking and analysis of information changes in the science communication process, but this requires systems to understand the similarity between scientific information across multiple domains. To this end, we present the SCIENTIFIC PARAPHRASE AND INFORMATION CHANGE DATASET (SPICED), the first paraphrase dataset of scientific findings annotated for degree of information change. SPICED contains 6,000 scientific finding pairs extracted from news stories, social media discussions, and full texts of original papers. We demonstrate that SPICED poses a challenging task and that models trained on SPICED improve downstream performance on evidence retrieval for fact checking of real-world scientific claims. Finally, we show that models trained on SPICED can reveal large-scale trends in the degrees to which people and organizations faithfully communicate new scientific findings. Data, code, and pre-trained models are available at http://www.copenlu.com/publication/2022_emnlp_wright/.
A Neighborhood Framework for Resource-Lean Content Flagging
Sheikh Muhammad Sarwar | Dimitrina Zlatkova | Momchil Hardalov | Yoan Dinkov | Isabelle Augenstein | Preslav Nakov
Transactions of the Association for Computational Linguistics, Volume 10
Sheikh Muhammad Sarwar | Dimitrina Zlatkova | Momchil Hardalov | Yoan Dinkov | Isabelle Augenstein | Preslav Nakov
Transactions of the Association for Computational Linguistics, Volume 10
We propose a novel framework for cross- lingual content flagging with limited target- language data, which significantly outperforms prior work in terms of predictive performance. The framework is based on a nearest-neighbor architecture. It is a modern instantiation of the vanilla k-nearest neighbor model, as we use Transformer representations in all its components. Our framework can adapt to new source- language instances, without the need to be retrained from scratch. Unlike prior work on neighborhood-based approaches, we encode the neighborhood information based on query– neighbor interactions. We propose two encoding schemes and we show their effectiveness using both qualitative and quantitative analysis. Our evaluation results on eight languages from two different datasets for abusive language detection show sizable improvements of up to 9.5 F1 points absolute (for Italian) over strong baselines. On average, we achieve 3.6 absolute F1 points of improvement for the three languages in the Jigsaw Multilingual dataset and 2.14 points for the WUL dataset.
2021
Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Tutorial Abstracts
Isabelle Augenstein | Ivan Habernal
Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Tutorial Abstracts
Isabelle Augenstein | Ivan Habernal
Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Tutorial Abstracts
Does Typological Blinding Impede Cross-Lingual Sharing?
Johannes Bjerva | Isabelle Augenstein
Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume
Johannes Bjerva | Isabelle Augenstein
Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume
Bridging the performance gap between high- and low-resource languages has been the focus of much previous work. Typological features from databases such as the World Atlas of Language Structures (WALS) are a prime candidate for this, as such data exists even for very low-resource languages. However, previous work has only found minor benefits from using typological information. Our hypothesis is that a model trained in a cross-lingual setting will pick up on typological cues from the input data, thus overshadowing the utility of explicitly using such features. We verify this hypothesis by blinding a model to typological information, and investigate how cross-lingual sharing and performance is impacted. Our model is based on a cross-lingual architecture in which the latent weights governing the sharing between languages is learnt during training. We show that (i) preventing this model from exploiting typology severely reduces performance, while a control experiment reaffirms that (ii) encouraging sharing according to typology somewhat improves performance.
Determining the Credibility of Science Communication
Isabelle Augenstein
Proceedings of the Second Workshop on Scholarly Document Processing
Isabelle Augenstein
Proceedings of the Second Workshop on Scholarly Document Processing
Most work on scholarly document processing assumes that the information processed is trust-worthy and factually correct. However, this is not always the case. There are two core challenges, which should be addressed: 1) ensuring that scientific publications are credible – e.g. that claims are not made without supporting evidence, and that all relevant supporting evidence is provided; and 2) that scientific findings are not misrepresented, distorted or outright misreported when communicated by journalists or the general public. I will present some first steps towards addressing these problems and outline remaining challenges.
How Does Counterfactually Augmented Data Impact Models for Social Computing Constructs?
Indira Sen | Mattia Samory | Fabian Flöck | Claudia Wagner | Isabelle Augenstein
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
Indira Sen | Mattia Samory | Fabian Flöck | Claudia Wagner | Isabelle Augenstein
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
As NLP models are increasingly deployed in socially situated settings such as online abusive content detection, it is crucial to ensure that these models are robust. One way of improving model robustness is to generate counterfactually augmented data (CAD) for training models that can better learn to distinguish between core features and data artifacts. While models trained on this type of data have shown promising out-of-domain generalizability, it is still unclear what the sources of such improvements are. We investigate the benefits of CAD for social NLP models by focusing on three social computing constructs — sentiment, sexism, and hate speech. Assessing the performance of models trained with and without CAD across different types of datasets, we find that while models trained on CAD show lower in-domain performance, they generalize better out-of-domain. We unpack this apparent discrepancy using machine explanations and find that CAD reduces model reliance on spurious features. Leveraging a novel typology of CAD to analyze their relationship with model performance, we find that CAD which acts on the construct directly or a diverse set of CAD leads to higher performance.
Semi-Supervised Exaggeration Detection of Health Science Press Releases
Dustin Wright | Isabelle Augenstein
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
Dustin Wright | Isabelle Augenstein
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
Public trust in science depends on honest and factual communication of scientific papers. However, recent studies have demonstrated a tendency of news media to misrepresent scientific papers by exaggerating their findings. Given this, we present a formalization of and study into the problem of exaggeration detection in science communication. While there are an abundance of scientific papers and popular media articles written about them, very rarely do the articles include a direct link to the original paper, making data collection challenging, and necessitating the need for few-shot learning. We address this by curating a set of labeled press release/abstract pairs from existing expert annotated studies on exaggeration in press releases of scientific papers suitable for benchmarking the performance of machine learning models on the task. Using limited data from this and previous studies on exaggeration detection in science, we introduce MT-PET, a multi-task version of Pattern Exploiting Training (PET), which leverages knowledge from complementary cloze-style QA tasks to improve few-shot learning. We demonstrate that MT-PET outperforms PET and supervised learning both when data is limited, as well as when there is an abundance of data for the main task.
Cross-Domain Label-Adaptive Stance Detection
Momchil Hardalov | Arnav Arora | Preslav Nakov | Isabelle Augenstein
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
Momchil Hardalov | Arnav Arora | Preslav Nakov | Isabelle Augenstein
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
Stance detection concerns the classification of a writer’s viewpoint towards a target. There are different task variants, e.g., stance of a tweet vs. a full article, or stance with respect to a claim vs. an (implicit) topic. Moreover, task definitions vary, which includes the label inventory, the data collection, and the annotation protocol. All these aspects hinder cross-domain studies, as they require changes to standard domain adaptation approaches. In this paper, we perform an in-depth analysis of 16 stance detection datasets, and we explore the possibility for cross-domain learning from them. Moreover, we propose an end-to-end unsupervised framework for out-of-domain prediction of unseen, user-defined labels. In particular, we combine domain adaptation techniques such as mixture of experts and domain-adversarial training with label embeddings, and we demonstrate sizable performance gains over strong baselines, both (i) in-domain, i.e., for seen targets, and (ii) out-of-domain, i.e., for unseen targets. Finally, we perform an exhaustive analysis of the cross-domain results, and we highlight the important factors influencing the model performance.
Is Sparse Attention more Interpretable?
Clara Meister | Stefan Lazov | Isabelle Augenstein | Ryan Cotterell
Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers)
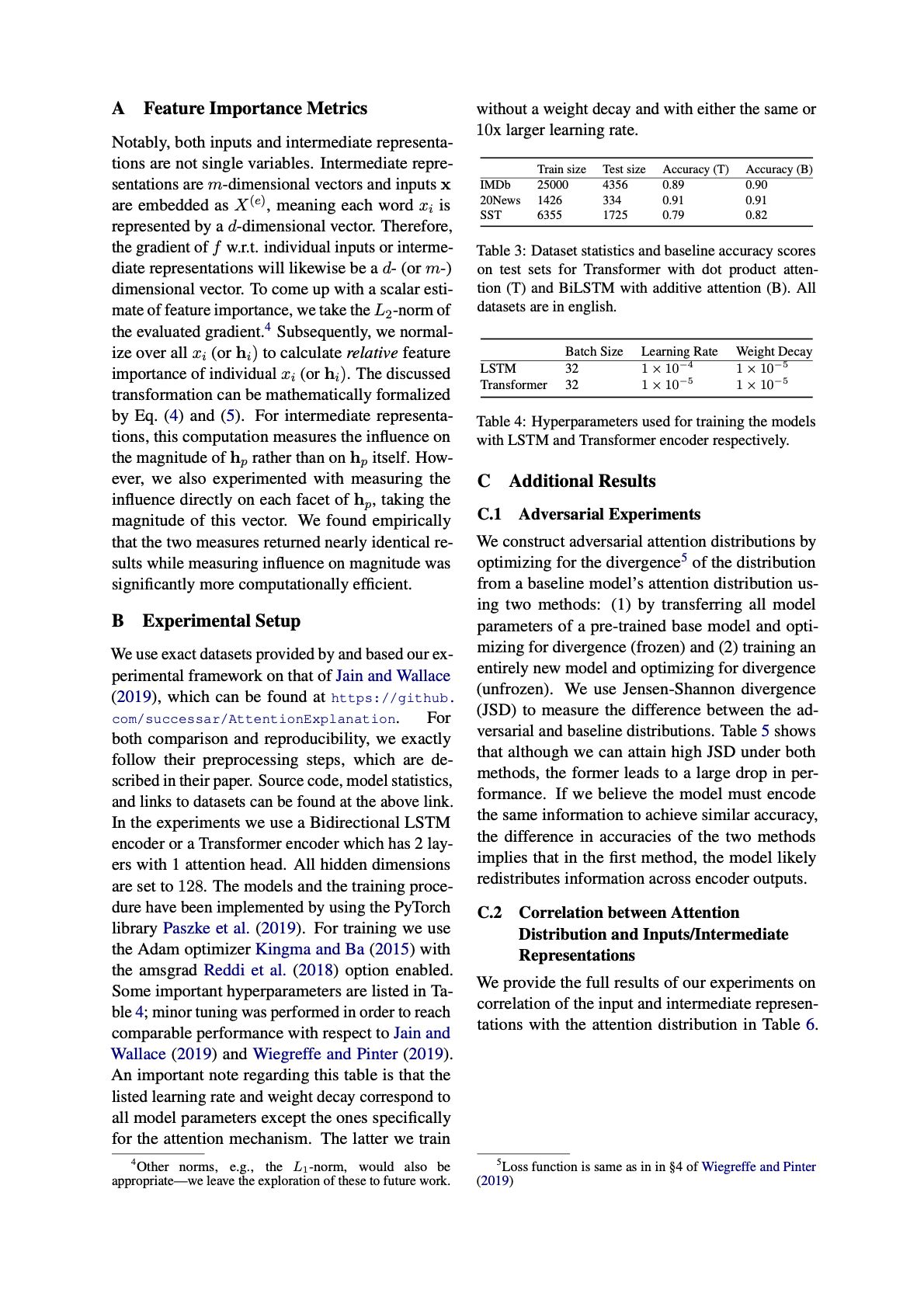{kind=link}
Clara Meister | Stefan Lazov | Isabelle Augenstein | Ryan Cotterell
Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers)
Sparse attention has been claimed to increase model interpretability under the assumption that it highlights influential inputs. Yet the attention distribution is typically over representations internal to the model rather than the inputs themselves, suggesting this assumption may not have merit. We build on the recent work exploring the interpretability of attention; we design a set of experiments to help us understand how sparsity affects our ability to use attention as an explainability tool. On three text classification tasks, we verify that only a weak relationship between inputs and co-indexed intermediate representations exists—under sparse attention and otherwise. Further, we do not find any plausible mappings from sparse attention distributions to a sparse set of influential inputs through other avenues. Rather, we observe in this setting that inducing sparsity may make it less plausible that attention can be used as a tool for understanding model behavior.
Inducing Language-Agnostic Multilingual Representations
Wei Zhao | Steffen Eger | Johannes Bjerva | Isabelle Augenstein
Proceedings of *SEM 2021: The Tenth Joint Conference on Lexical and Computational Semantics
Wei Zhao | Steffen Eger | Johannes Bjerva | Isabelle Augenstein
Proceedings of *SEM 2021: The Tenth Joint Conference on Lexical and Computational Semantics
Cross-lingual representations have the potential to make NLP techniques available to the vast majority of languages in the world. However, they currently require large pretraining corpora or access to typologically similar languages. In this work, we address these obstacles by removing language identity signals from multilingual embeddings. We examine three approaches for this: (i) re-aligning the vector spaces of target languages (all together) to a pivot source language; (ii) removing language-specific means and variances, which yields better discriminativeness of embeddings as a by-product; and (iii) increasing input similarity across languages by removing morphological contractions and sentence reordering. We evaluate on XNLI and reference-free MT evaluation across 19 typologically diverse languages. Our findings expose the limitations of these approaches—unlike vector normalization, vector space re-alignment and text normalization do not achieve consistent gains across encoders and languages. Due to the approaches’ additive effects, their combination decreases the cross-lingual transfer gap by 8.9 points (m-BERT) and 18.2 points (XLM-R) on average across all tasks and languages, however.
CiteWorth: Cite-Worthiness Detection for Improved Scientific Document Understanding
Dustin Wright | Isabelle Augenstein
Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021
Dustin Wright | Isabelle Augenstein
Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021
2020
2kenize: Tying Subword Sequences for Chinese Script Conversion
Pranav A | Isabelle Augenstein
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics
Pranav A | Isabelle Augenstein
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics
Simplified Chinese to Traditional Chinese character conversion is a common preprocessing step in Chinese NLP. Despite this, current approaches have insufficient performance because they do not take into account that a simplified Chinese character can correspond to multiple traditional characters. Here, we propose a model that can disambiguate between mappings and convert between the two scripts. The model is based on subword segmentation, two language models, as well as a method for mapping between subword sequences. We further construct benchmark datasets for topic classification and script conversion. Our proposed method outperforms previous Chinese Character conversion approaches by 6 points in accuracy. These results are further confirmed in a downstream application, where 2kenize is used to convert pretraining dataset for topic classification. An error analysis reveals that our method’s particular strengths are in dealing with code mixing and named entities.
Zero-Shot Cross-Lingual Transfer with Meta Learning
Farhad Nooralahzadeh | Giannis Bekoulis | Johannes Bjerva | Isabelle Augenstein
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Farhad Nooralahzadeh | Giannis Bekoulis | Johannes Bjerva | Isabelle Augenstein
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Learning what to share between tasks has become a topic of great importance, as strategic sharing of knowledge has been shown to improve downstream task performance. This is particularly important for multilingual applications, as most languages in the world are under-resourced. Here, we consider the setting of training models on multiple different languages at the same time, when little or no data is available for languages other than English. We show that this challenging setup can be approached using meta-learning: in addition to training a source language model, another model learns to select which training instances are the most beneficial to the first. We experiment using standard supervised, zero-shot cross-lingual, as well as few-shot cross-lingual settings for different natural language understanding tasks (natural language inference, question answering). Our extensive experimental setup demonstrates the consistent effectiveness of meta-learning for a total of 15 languages. We improve upon the state-of-the-art for zero-shot and few-shot NLI (on MultiNLI and XNLI) and QA (on the MLQA dataset). A comprehensive error analysis indicates that the correlation of typological features between languages can partly explain when parameter sharing learned via meta-learning is beneficial.
Generating Fact Checking Explanations
Pepa Atanasova | Jakob Grue Simonsen | Christina Lioma | Isabelle Augenstein
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics
Pepa Atanasova | Jakob Grue Simonsen | Christina Lioma | Isabelle Augenstein
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics
Most existing work on automated fact checking is concerned with predicting the veracity of claims based on metadata, social network spread, language used in claims, and, more recently, evidence supporting or denying claims. A crucial piece of the puzzle that is still missing is to understand how to automate the most elaborate part of the process – generating justifications for verdicts on claims. This paper provides the first study of how these explanations can be generated automatically based on available claim context, and how this task can be modelled jointly with veracity prediction. Our results indicate that optimising both objectives at the same time, rather than training them separately, improves the performance of a fact checking system. The results of a manual evaluation further suggest that the informativeness, coverage and overall quality of the generated explanations are also improved in the multi-task model.
A Diagnostic Study of Explainability Techniques for Text Classification
Pepa Atanasova | Jakob Grue Simonsen | Christina Lioma | Isabelle Augenstein
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Pepa Atanasova | Jakob Grue Simonsen | Christina Lioma | Isabelle Augenstein
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Recent developments in machine learning have introduced models that approach human performance at the cost of increased architectural complexity. Efforts to make the rationales behind the models’ predictions transparent have inspired an abundance of new explainability techniques. Provided with an already trained model, they compute saliency scores for the words of an input instance. However, there exists no definitive guide on (i) how to choose such a technique given a particular application task and model architecture, and (ii) the benefits and drawbacks of using each such technique. In this paper, we develop a comprehensive list of diagnostic properties for evaluating existing explainability techniques. We then employ the proposed list to compare a set of diverse explainability techniques on downstream text classification tasks and neural network architectures. We also compare the saliency scores assigned by the explainability techniques with human annotations of salient input regions to find relations between a model’s performance and the agreement of its rationales with human ones. Overall, we find that the gradient-based explanations perform best across tasks and model architectures, and we present further insights into the properties of the reviewed explainability techniques.
Generating Label Cohesive and Well-Formed Adversarial Claims
Pepa Atanasova | Dustin Wright | Isabelle Augenstein
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Pepa Atanasova | Dustin Wright | Isabelle Augenstein
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Adversarial attacks reveal important vulnerabilities and flaws of trained models. One potent type of attack are universal adversarial triggers, which are individual n-grams that, when appended to instances of a class under attack, can trick a model into predicting a target class. However, for inference tasks such as fact checking, these triggers often inadvertently invert the meaning of instances they are inserted in. In addition, such attacks produce semantically nonsensical inputs, as they simply concatenate triggers to existing samples. Here, we investigate how to generate adversarial attacks against fact checking systems that preserve the ground truth meaning and are semantically valid. We extend the HotFlip attack algorithm used for universal trigger generation by jointly minimizing the target class loss of a fact checking model and the entailment class loss of an auxiliary natural language inference model. We then train a conditional language model to generate semantically valid statements, which include the found universal triggers. We find that the generated attacks maintain the directionality and semantic validity of the claim better than previous work.
Unsupervised Evaluation for Question Answering with Transformers
Lukas Muttenthaler | Isabelle Augenstein | Johannes Bjerva
Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP
Lukas Muttenthaler | Isabelle Augenstein | Johannes Bjerva
Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP
It is challenging to automatically evaluate the answer of a QA model at inference time. Although many models provide confidence scores, and simple heuristics can go a long way towards indicating answer correctness, such measures are heavily dataset-dependent and are unlikely to generalise. In this work, we begin by investigating the hidden representations of questions, answers, and contexts in transformer-based QA architectures. We observe a consistent pattern in the answer representations, which we show can be used to automatically evaluate whether or not a predicted answer span is correct. Our method does not require any labelled data and outperforms strong heuristic baselines, across 2 datasets and 7 domains. We are able to predict whether or not a model’s answer is correct with 91.37% accuracy on SQuAD, and 80.7% accuracy on SubjQA. We expect that this method will have broad applications, e.g., in semi-automatic development of QA datasets.
What Can We Do to Improve Peer Review in NLP?
Anna Rogers | Isabelle Augenstein
Findings of the Association for Computational Linguistics: EMNLP 2020
Anna Rogers | Isabelle Augenstein
Findings of the Association for Computational Linguistics: EMNLP 2020
Peer review is our best tool for judging the quality of conference submissions, but it is becoming increasingly spurious. We argue that a part of the problem is that the reviewers and area chairs face a poorly defined task forcing apples-to-oranges comparisons. There are several potential ways forward, but the key difficulty is creating the incentives and mechanisms for their consistent implementation in the NLP community.
Claim Check-Worthiness Detection as Positive Unlabelled Learning
Dustin Wright | Isabelle Augenstein
Findings of the Association for Computational Linguistics: EMNLP 2020
Dustin Wright | Isabelle Augenstein
Findings of the Association for Computational Linguistics: EMNLP 2020
As the first step of automatic fact checking, claim check-worthiness detection is a critical component of fact checking systems. There are multiple lines of research which study this problem: check-worthiness ranking from political speeches and debates, rumour detection on Twitter, and citation needed detection from Wikipedia. To date, there has been no structured comparison of these various tasks to understand their relatedness, and no investigation into whether or not a unified approach to all of them is achievable. In this work, we illuminate a central challenge in claim check-worthiness detection underlying all of these tasks, being that they hinge upon detecting both how factual a sentence is, as well as how likely a sentence is to be believed without verification. As such, annotators only mark those instances they judge to be clear-cut check-worthy. Our best performing method is a unified approach which automatically corrects for this using a variant of positive unlabelled learning that finds instances which were incorrectly labelled as not check-worthy. In applying this, we out-perform the state of the art in two of the three tasks studied for claim check-worthiness detection in English.
SubjQA: A Dataset for Subjectivity and Review Comprehension
Johannes Bjerva | Nikita Bhutani | Behzad Golshan | Wang-Chiew Tan | Isabelle Augenstein
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Johannes Bjerva | Nikita Bhutani | Behzad Golshan | Wang-Chiew Tan | Isabelle Augenstein
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Subjectivity is the expression of internal opinions or beliefs which cannot be objectively observed or verified, and has been shown to be important for sentiment analysis and word-sense disambiguation. Furthermore, subjectivity is an important aspect of user-generated data. In spite of this, subjectivity has not been investigated in contexts where such data is widespread, such as in question answering (QA). We develop a new dataset which allows us to investigate this relationship. We find that subjectivity is an important feature in the case of QA, albeit with more intricate interactions between subjectivity and QA performance than found in previous work on sentiment analysis. For instance, a subjective question may or may not be associated with a subjective answer. We release an English QA dataset (SubjQA) based on customer reviews, containing subjectivity annotations for questions and answer spans across 6 domains.
SIGTYP 2020 Shared Task: Prediction of Typological Features
Johannes Bjerva | Elizabeth Salesky | Sabrina J. Mielke | Aditi Chaudhary | Giuseppe G. A. Celano | Edoardo Maria Ponti | Ekaterina Vylomova | Ryan Cotterell | Isabelle Augenstein
Proceedings of the Second Workshop on Computational Research in Linguistic Typology
Johannes Bjerva | Elizabeth Salesky | Sabrina J. Mielke | Aditi Chaudhary | Giuseppe G. A. Celano | Edoardo Maria Ponti | Ekaterina Vylomova | Ryan Cotterell | Isabelle Augenstein
Proceedings of the Second Workshop on Computational Research in Linguistic Typology
Typological knowledge bases (KBs) such as WALS (Dryer and Haspelmath, 2013) contain information about linguistic properties of the world’s languages. They have been shown to be useful for downstream applications, including cross-lingual transfer learning and linguistic probing. A major drawback hampering broader adoption of typological KBs is that they are sparsely populated, in the sense that most languages only have annotations for some features, and skewed, in that few features have wide coverage. As typological features often correlate with one another, it is possible to predict them and thus automatically populate typological KBs, which is also the focus of this shared task. Overall, the task attracted 8 submissions from 5 teams, out of which the most successful methods make use of such feature correlations. However, our error analysis reveals that even the strongest submitted systems struggle with predicting feature values for languages where few features are known.
Transformer Based Multi-Source Domain Adaptation
Dustin Wright | Isabelle Augenstein
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Dustin Wright | Isabelle Augenstein
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
In practical machine learning settings, the data on which a model must make predictions often come from a different distribution than the data it was trained on. Here, we investigate the problem of unsupervised multi-source domain adaptation, where a model is trained on labelled data from multiple source domains and must make predictions on a domain for which no labelled data has been seen. Prior work with CNNs and RNNs has demonstrated the benefit of mixture of experts, where the predictions of multiple domain expert classifiers are combined; as well as domain adversarial training, to induce a domain agnostic representation space. Inspired by this, we investigate how such methods can be effectively applied to large pretrained transformer models. We find that domain adversarial training has an effect on the learned representations of these models while having little effect on their performance, suggesting that large transformer-based models are already relatively robust across domains. Additionally, we show that mixture of experts leads to significant performance improvements by comparing several variants of mixing functions, including one novel metric based on attention. Finally, we demonstrate that the predictions of large pretrained transformer based domain experts are highly homogenous, making it challenging to learn effective metrics for mixing their predictions.
2019
Combining Sentiment Lexica with a Multi-View Variational Autoencoder
Alexander Hoyle | Lawrence Wolf-Sonkin | Hanna Wallach | Ryan Cotterell | Isabelle Augenstein
Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)
Alexander Hoyle | Lawrence Wolf-Sonkin | Hanna Wallach | Ryan Cotterell | Isabelle Augenstein
Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)
When assigning quantitative labels to a dataset, different methodologies may rely on different scales. In particular, when assigning polarities to words in a sentiment lexicon, annotators may use binary, categorical, or continuous labels. Naturally, it is of interest to unify these labels from disparate scales to both achieve maximal coverage over words and to create a single, more robust sentiment lexicon while retaining scale coherence. We introduce a generative model of sentiment lexica to combine disparate scales into a common latent representation. We realize this model with a novel multi-view variational autoencoder (VAE), called SentiVAE. We evaluate our approach via a downstream text classification task involving nine English-Language sentiment analysis datasets; our representation outperforms six individual sentiment lexica, as well as a straightforward combination thereof.
Uncovering Probabilistic Implications in Typological Knowledge Bases
Johannes Bjerva | Yova Kementchedjhieva | Ryan Cotterell | Isabelle Augenstein
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics
Johannes Bjerva | Yova Kementchedjhieva | Ryan Cotterell | Isabelle Augenstein
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics
The study of linguistic typology is rooted in the implications we find between linguistic features, such as the fact that languages with object-verb word ordering tend to have postpositions. Uncovering such implications typically amounts to time-consuming manual processing by trained and experienced linguists, which potentially leaves key linguistic universals unexplored. In this paper, we present a computational model which successfully identifies known universals, including Greenberg universals, but also uncovers new ones, worthy of further linguistic investigation. Our approach outperforms baselines previously used for this problem, as well as a strong baseline from knowledge base population.
X-WikiRE: A Large, Multilingual Resource for Relation Extraction as Machine Comprehension
Mostafa Abdou | Cezar Sas | Rahul Aralikatte | Isabelle Augenstein | Anders Søgaard
Proceedings of the 2nd Workshop on Deep Learning Approaches for Low-Resource NLP (DeepLo 2019)
Mostafa Abdou | Cezar Sas | Rahul Aralikatte | Isabelle Augenstein | Anders Søgaard
Proceedings of the 2nd Workshop on Deep Learning Approaches for Low-Resource NLP (DeepLo 2019)
Although the vast majority of knowledge bases (KBs) are heavily biased towards English, Wikipedias do cover very different topics in different languages. Exploiting this, we introduce a new multilingual dataset (X-WikiRE), framing relation extraction as a multilingual machine reading problem. We show that by leveraging this resource it is possible to robustly transfer models cross-lingually and that multilingual support significantly improves (zero-shot) relation extraction, enabling the population of low-resourced KBs from their well-populated counterparts.
Proceedings of the 4th Workshop on Representation Learning for NLP (RepL4NLP-2019)
Isabelle Augenstein | Spandana Gella | Sebastian Ruder | Katharina Kann | Burcu Can | Johannes Welbl | Alexis Conneau | Xiang Ren | Marek Rei
Proceedings of the 4th Workshop on Representation Learning for NLP (RepL4NLP-2019)
Isabelle Augenstein | Spandana Gella | Sebastian Ruder | Katharina Kann | Burcu Can | Johannes Welbl | Alexis Conneau | Xiang Ren | Marek Rei
Proceedings of the 4th Workshop on Representation Learning for NLP (RepL4NLP-2019)
Mapping (Dis-)Information Flow about the MH17 Plane Crash
Mareike Hartmann | Yevgeniy Golovchenko | Isabelle Augenstein
Proceedings of the Second Workshop on Natural Language Processing for Internet Freedom: Censorship, Disinformation, and Propaganda
Mareike Hartmann | Yevgeniy Golovchenko | Isabelle Augenstein
Proceedings of the Second Workshop on Natural Language Processing for Internet Freedom: Censorship, Disinformation, and Propaganda
Digital media enables not only fast sharing of information, but also disinformation. One prominent case of an event leading to circulation of disinformation on social media is the MH17 plane crash. Studies analysing the spread of information about this event on Twitter have focused on small, manually annotated datasets, or used proxys for data annotation. In this work, we examine to what extent text classifiers can be used to label data for subsequent content analysis, in particular we focus on predicting pro-Russian and pro-Ukrainian Twitter content related to the MH17 plane crash. Even though we find that a neural classifier improves over a hashtag based baseline, labeling pro-Russian and pro-Ukrainian content with high precision remains a challenging problem. We provide an error analysis underlining the difficulty of the task and identify factors that might help improve classification in future work. Finally, we show how the classifier can facilitate the annotation task for human annotators.
Transductive Auxiliary Task Self-Training for Neural Multi-Task Models
Johannes Bjerva | Katharina Kann | Isabelle Augenstein
Proceedings of the 2nd Workshop on Deep Learning Approaches for Low-Resource NLP (DeepLo 2019)
Johannes Bjerva | Katharina Kann | Isabelle Augenstein
Proceedings of the 2nd Workshop on Deep Learning Approaches for Low-Resource NLP (DeepLo 2019)
Multi-task learning and self-training are two common ways to improve a machine learning model’s performance in settings with limited training data. Drawing heavily on ideas from those two approaches, we suggest transductive auxiliary task self-training: training a multi-task model on (i) a combination of main and auxiliary task training data, and (ii) test instances with auxiliary task labels which a single-task version of the model has previously generated. We perform extensive experiments on 86 combinations of languages and tasks. Our results are that, on average, transductive auxiliary task self-training improves absolute accuracy by up to 9.56% over the pure multi-task model for dependency relation tagging and by up to 13.03% for semantic tagging.
MultiFC: A Real-World Multi-Domain Dataset for Evidence-Based Fact Checking of Claims
Isabelle Augenstein | Christina Lioma | Dongsheng Wang | Lucas Chaves Lima | Casper Hansen | Christian Hansen | Jakob Grue Simonsen
Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)
Isabelle Augenstein | Christina Lioma | Dongsheng Wang | Lucas Chaves Lima | Casper Hansen | Christian Hansen | Jakob Grue Simonsen
Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)
We contribute the largest publicly available dataset of naturally occurring factual claims for the purpose of automatic claim verification. It is collected from 26 fact checking websites in English, paired with textual sources and rich metadata, and labelled for veracity by human expert journalists. We present an in-depth analysis of the dataset, highlighting characteristics and challenges. Further, we present results for automatic veracity prediction, both with established baselines and with a novel method for joint ranking of evidence pages and predicting veracity that outperforms all baselines. Significant performance increases are achieved by encoding evidence, and by modelling metadata. Our best-performing model achieves a Macro F1 of 49.2%, showing that this is a challenging testbed for claim veracity prediction.
A Probabilistic Generative Model of Linguistic Typology
Johannes Bjerva | Yova Kementchedjhieva | Ryan Cotterell | Isabelle Augenstein
Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)
Johannes Bjerva | Yova Kementchedjhieva | Ryan Cotterell | Isabelle Augenstein
Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)
In the principles-and-parameters framework, the structural features of languages depend on parameters that may be toggled on or off, with a single parameter often dictating the status of multiple features. The implied covariance between features inspires our probabilisation of this line of linguistic inquiry—we develop a generative model of language based on exponential-family matrix factorisation. By modelling all languages and features within the same architecture, we show how structural similarities between languages can be exploited to predict typological features with near-perfect accuracy, outperforming several baselines on the task of predicting held-out features. Furthermore, we show that language embeddings pre-trained on monolingual text allow for generalisation to unobserved languages. This finding has clear practical and also theoretical implications: the results confirm what linguists have hypothesised, i.e. that there are significant correlations between typological features and languages.
Unsupervised Discovery of Gendered Language through Latent-Variable Modeling
Alexander Hoyle | Lawrence Wolf-Sonkin | Hanna Wallach | Isabelle Augenstein | Ryan Cotterell
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics
Alexander Hoyle | Lawrence Wolf-Sonkin | Hanna Wallach | Isabelle Augenstein | Ryan Cotterell
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics
Studying the ways in which language is gendered has long been an area of interest in sociolinguistics. Studies have explored, for example, the speech of male and female characters in film and the language used to describe male and female politicians. In this paper, we aim not to merely study this phenomenon qualitatively, but instead to quantify the degree to which the language used to describe men and women is different and, moreover, different in a positive or negative way. To that end, we introduce a generative latent-variable model that jointly represents adjective (or verb) choice, with its sentiment, given the natural gender of a head (or dependent) noun. We find that there are significant differences between descriptions of male and female nouns and that these differences align with common gender stereotypes: Positive adjectives used to describe women are more often related to their bodies than adjectives used to describe men.
Issue Framing in Online Discussion Fora
Mareike Hartmann | Tallulah Jansen | Isabelle Augenstein | Anders Søgaard
Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)
Mareike Hartmann | Tallulah Jansen | Isabelle Augenstein | Anders Søgaard
Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)
In online discussion fora, speakers often make arguments for or against something, say birth control, by highlighting certain aspects of the topic. In social science, this is referred to as issue framing. In this paper, we introduce a new issue frame annotated corpus of online discussions. We explore to what extent models trained to detect issue frames in newswire and social media can be transferred to the domain of discussion fora, using a combination of multi-task and adversarial training, assuming only unlabeled training data in the target domain.
What Do Language Representations Really Represent?
Johannes Bjerva | Robert Östling | Maria Han Veiga | Jörg Tiedemann | Isabelle Augenstein
Computational Linguistics, Volume 45, Issue 2 - June 2019
Johannes Bjerva | Robert Östling | Maria Han Veiga | Jörg Tiedemann | Isabelle Augenstein
Computational Linguistics, Volume 45, Issue 2 - June 2019
A neural language model trained on a text corpus can be used to induce distributed representations of words, such that similar words end up with similar representations. If the corpus is multilingual, the same model can be used to learn distributed representations of languages, such that similar languages end up with similar representations. We show that this holds even when the multilingual corpus has been translated into English, by picking up the faint signal left by the source languages. However, just as it is a thorny problem to separate semantic from syntactic similarity in word representations, it is not obvious what type of similarity is captured by language representations. We investigate correlations and causal relationships between language representations learned from translations on one hand, and genetic, geographical, and several levels of structural similarity between languages on the other. Of these, structural similarity is found to correlate most strongly with language representation similarity, whereas genetic relationships—a convenient benchmark used for evaluation in previous work—appears to be a confounding factor. Apart from implications about translation effects, we see this more generally as a case where NLP and linguistic typology can interact and benefit one another.
2018
Nightmare at test time: How punctuation prevents parsers from generalizing
Anders Søgaard | Miryam de Lhoneux | Isabelle Augenstein
Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP
Anders Søgaard | Miryam de Lhoneux | Isabelle Augenstein
Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP
Punctuation is a strong indicator of syntactic structure, and parsers trained on text with punctuation often rely heavily on this signal. Punctuation is a diversion, however, since human language processing does not rely on punctuation to the same extent, and in informal texts, we therefore often leave out punctuation. We also use punctuation ungrammatically for emphatic or creative purposes, or simply by mistake. We show that (a) dependency parsers are sensitive to both absence of punctuation and to alternative uses; (b) neural parsers tend to be more sensitive than vintage parsers; (c) training neural parsers without punctuation outperforms all out-of-the-box parsers across all scenarios where punctuation departs from standard punctuation. Our main experiments are on synthetically corrupted data to study the effect of punctuation in isolation and avoid potential confounds, but we also show effects on out-of-domain data.
A strong baseline for question relevancy ranking
Ana Gonzalez | Isabelle Augenstein | Anders Søgaard
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing
Ana Gonzalez | Isabelle Augenstein | Anders Søgaard
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing
The best systems at the SemEval-16 and SemEval-17 community question answering shared tasks – a task that amounts to question relevancy ranking – involve complex pipelines and manual feature engineering. Despite this, many of these still fail at beating the IR baseline, i.e., the rankings provided by Google’s search engine. We present a strong baseline for question relevancy ranking by training a simple multi-task feed forward network on a bag of 14 distance measures for the input question pair. This baseline model, which is fast to train and uses only language-independent features, outperforms the best shared task systems on the task of retrieving relevant previously asked questions.
Multi-Task Learning of Pairwise Sequence Classification Tasks over Disparate Label Spaces
Isabelle Augenstein | Sebastian Ruder | Anders Søgaard
Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers)
Isabelle Augenstein | Sebastian Ruder | Anders Søgaard
Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers)
We combine multi-task learning and semi-supervised learning by inducing a joint embedding space between disparate label spaces and learning transfer functions between label embeddings, enabling us to jointly leverage unlabelled data and auxiliary, annotated datasets. We evaluate our approach on a variety of tasks with disparate label spaces. We outperform strong single and multi-task baselines and achieve a new state of the art for aspect-based and topic-based sentiment analysis.
Proceedings of the Third Workshop on Representation Learning for NLP
Isabelle Augenstein | Kris Cao | He He | Felix Hill | Spandana Gella | Jamie Kiros | Hongyuan Mei | Dipendra Misra
Proceedings of the Third Workshop on Representation Learning for NLP
Isabelle Augenstein | Kris Cao | He He | Felix Hill | Spandana Gella | Jamie Kiros | Hongyuan Mei | Dipendra Misra
Proceedings of the Third Workshop on Representation Learning for NLP
Character-level Supervision for Low-resource POS Tagging
Katharina Kann | Johannes Bjerva | Isabelle Augenstein | Barbara Plank | Anders Søgaard
Proceedings of the Workshop on Deep Learning Approaches for Low-Resource NLP
Katharina Kann | Johannes Bjerva | Isabelle Augenstein | Barbara Plank | Anders Søgaard
Proceedings of the Workshop on Deep Learning Approaches for Low-Resource NLP
Neural part-of-speech (POS) taggers are known to not perform well with little training data. As a step towards overcoming this problem, we present an architecture for learning more robust neural POS taggers by jointly training a hierarchical, recurrent model and a recurrent character-based sequence-to-sequence network supervised using an auxiliary objective. This way, we introduce stronger character-level supervision into the model, which enables better generalization to unseen words and provides regularization, making our encoding less prone to overfitting. We experiment with three auxiliary tasks: lemmatization, character-based word autoencoding, and character-based random string autoencoding. Experiments with minimal amounts of labeled data on 34 languages show that our new architecture outperforms a single-task baseline and, surprisingly, that, on average, raw text autoencoding can be as beneficial for low-resource POS tagging as using lemma information. Our neural POS tagger closes the gap to a state-of-the-art POS tagger (MarMoT) for low-resource scenarios by 43%, even outperforming it on languages with templatic morphology, e.g., Arabic, Hebrew, and Turkish, by some margin.
KU-MTL at SemEval-2018 Task 1: Multi-task Identification of Affect in Tweets
Thomas Nyegaard-Signori | Casper Veistrup Helms | Johannes Bjerva | Isabelle Augenstein
Proceedings of the 12th International Workshop on Semantic Evaluation
Thomas Nyegaard-Signori | Casper Veistrup Helms | Johannes Bjerva | Isabelle Augenstein
Proceedings of the 12th International Workshop on Semantic Evaluation
We take a multi-task learning approach to the shared Task 1 at SemEval-2018. The general idea concerning the model structure is to use as little external data as possible in order to preserve the task relatedness and reduce complexity. We employ multi-task learning with hard parameter sharing to exploit the relatedness between sub-tasks. As a base model, we use a standard recurrent neural network for both the classification and regression subtasks. Our system ranks 32nd out of 48 participants with a Pearson score of 0.557 in the first subtask, and 20th out of 35 in the fifth subtask with an accuracy score of 0.464.
Jack the Reader – A Machine Reading Framework
Dirk Weissenborn | Pasquale Minervini | Isabelle Augenstein | Johannes Welbl | Tim Rocktäschel | Matko Bošnjak | Jeff Mitchell | Thomas Demeester | Tim Dettmers | Pontus Stenetorp | Sebastian Riedel
Proceedings of ACL 2018, System Demonstrations
Dirk Weissenborn | Pasquale Minervini | Isabelle Augenstein | Johannes Welbl | Tim Rocktäschel | Matko Bošnjak | Jeff Mitchell | Thomas Demeester | Tim Dettmers | Pontus Stenetorp | Sebastian Riedel
Proceedings of ACL 2018, System Demonstrations
Many Machine Reading and Natural Language Understanding tasks require reading supporting text in order to answer questions. For example, in Question Answering, the supporting text can be newswire or Wikipedia articles; in Natural Language Inference, premises can be seen as the supporting text and hypotheses as questions. Providing a set of useful primitives operating in a single framework of related tasks would allow for expressive modelling, and easier model comparison and replication. To that end, we present Jack the Reader (JACK), a framework for Machine Reading that allows for quick model prototyping by component reuse, evaluation of new models on existing datasets as well as integrating new datasets and applying them on a growing set of implemented baseline models. JACK is currently supporting (but not limited to) three tasks: Question Answering, Natural Language Inference, and Link Prediction. It is developed with the aim of increasing research efficiency and code reuse.
Tracking Typological Traits of Uralic Languages in Distributed Language Representations
Johannes Bjerva | Isabelle Augenstein
Proceedings of the Fourth International Workshop on Computational Linguistics of Uralic Languages
Johannes Bjerva | Isabelle Augenstein
Proceedings of the Fourth International Workshop on Computational Linguistics of Uralic Languages
From Phonology to Syntax: Unsupervised Linguistic Typology at Different Levels with Language Embeddings
Johannes Bjerva | Isabelle Augenstein
Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers)
Johannes Bjerva | Isabelle Augenstein
Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers)
A core part of linguistic typology is the classification of languages according to linguistic properties, such as those detailed in the World Atlas of Language Structure (WALS). Doing this manually is prohibitively time-consuming, which is in part evidenced by the fact that only 100 out of over 7,000 languages spoken in the world are fully covered in WALS. We learn distributed language representations, which can be used to predict typological properties on a massively multilingual scale. Additionally, quantitative and qualitative analyses of these language embeddings can tell us how language similarities are encoded in NLP models for tasks at different typological levels. The representations are learned in an unsupervised manner alongside tasks at three typological levels: phonology (grapheme-to-phoneme prediction, and phoneme reconstruction), morphology (morphological inflection), and syntax (part-of-speech tagging). We consider more than 800 languages and find significant differences in the language representations encoded, depending on the target task. For instance, although Norwegian Bokmål and Danish are typologically close to one another, they are phonologically distant, which is reflected in their language embeddings growing relatively distant in a phonological task. We are also able to predict typological features in WALS with high accuracies, even for unseen language families.
Copenhagen at CoNLL–SIGMORPHON 2018: Multilingual Inflection in Context with Explicit Morphosyntactic Decoding
Yova Kementchedjhieva | Johannes Bjerva | Isabelle Augenstein
Proceedings of the CoNLL–SIGMORPHON 2018 Shared Task: Universal Morphological Reinflection
Yova Kementchedjhieva | Johannes Bjerva | Isabelle Augenstein
Proceedings of the CoNLL–SIGMORPHON 2018 Shared Task: Universal Morphological Reinflection
Parameter sharing between dependency parsers for related languages
Miryam de Lhoneux | Johannes Bjerva | Isabelle Augenstein | Anders Søgaard
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing
Miryam de Lhoneux | Johannes Bjerva | Isabelle Augenstein | Anders Søgaard
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing
Previous work has suggested that parameter sharing between transition-based neural dependency parsers for related languages can lead to better performance, but there is no consensus on what parameters to share. We present an evaluation of 27 different parameter sharing strategies across 10 languages, representing five pairs of related languages, each pair from a different language family. We find that sharing transition classifier parameters always helps, whereas the usefulness of sharing word and/or character LSTM parameters varies. Based on this result, we propose an architecture where the transition classifier is shared, and the sharing of word and character parameters is controlled by a parameter that can be tuned on validation data. This model is linguistically motivated and obtains significant improvements over a monolingually trained baseline. We also find that sharing transition classifier parameters helps when training a parser on unrelated language pairs, but we find that, in the case of unrelated languages, sharing too many parameters does not help.
2017
SemEval 2017 Task 10: ScienceIE - Extracting Keyphrases and Relations from Scientific Publications
Isabelle Augenstein | Mrinal Das | Sebastian Riedel | Lakshmi Vikraman | Andrew McCallum
Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017)
Isabelle Augenstein | Mrinal Das | Sebastian Riedel | Lakshmi Vikraman | Andrew McCallum
Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017)
We describe the SemEval task of extracting keyphrases and relations between them from scientific documents, which is crucial for understanding which publications describe which processes, tasks and materials. Although this was a new task, we had a total of 26 submissions across 3 evaluation scenarios. We expect the task and the findings reported in this paper to be relevant for researchers working on understanding scientific content, as well as the broader knowledge base population and information extraction communities.
Turing at SemEval-2017 Task 8: Sequential Approach to Rumour Stance Classification with Branch-LSTM
Elena Kochkina | Maria Liakata | Isabelle Augenstein
Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017)
Elena Kochkina | Maria Liakata | Isabelle Augenstein
Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017)
This paper describes team Turing’s submission to SemEval 2017 RumourEval: Determining rumour veracity and support for rumours (SemEval 2017 Task 8, Subtask A). Subtask A addresses the challenge of rumour stance classification, which involves identifying the attitude of Twitter users towards the truthfulness of the rumour they are discussing. Stance classification is considered to be an important step towards rumour verification, therefore performing well in this task is expected to be useful in debunking false rumours. In this work we classify a set of Twitter posts discussing rumours into either supporting, denying, questioning or commenting on the underlying rumours. We propose a LSTM-based sequential model that, through modelling the conversational structure of tweets, which achieves an accuracy of 0.784 on the RumourEval test set outperforming all other systems in Subtask A.
A Supervised Approach to Extractive Summarisation of Scientific Papers
Ed Collins | Isabelle Augenstein | Sebastian Riedel
Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017)
Ed Collins | Isabelle Augenstein | Sebastian Riedel
Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017)
Automatic summarisation is a popular approach to reduce a document to its main arguments. Recent research in the area has focused on neural approaches to summarisation, which can be very data-hungry. However, few large datasets exist and none for the traditionally popular domain of scientific publications, which opens up challenging research avenues centered on encoding large, complex documents. In this paper, we introduce a new dataset for summarisation of computer science publications by exploiting a large resource of author provided summaries and show straightforward ways of extending it further. We develop models on the dataset making use of both neural sentence encoding and traditionally used summarisation features and show that models which encode sentences as well as their local and global context perform best, significantly outperforming well-established baseline methods.
Multi-Task Learning of Keyphrase Boundary Classification
Isabelle Augenstein | Anders Søgaard
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)
Isabelle Augenstein | Anders Søgaard
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)
Keyphrase boundary classification (KBC) is the task of detecting keyphrases in scientific articles and labelling them with respect to predefined types. Although important in practice, this task is so far underexplored, partly due to the lack of labelled data. To overcome this, we explore several auxiliary tasks, including semantic super-sense tagging and identification of multi-word expressions, and cast the task as a multi-task learning problem with deep recurrent neural networks. Our multi-task models perform significantly better than previous state of the art approaches on two scientific KBC datasets, particularly for long keyphrases.
2016
USFD at SemEval-2016 Task 6: Any-Target Stance Detection on Twitter with Autoencoders
Isabelle Augenstein | Andreas Vlachos | Kalina Bontcheva
Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016)
Isabelle Augenstein | Andreas Vlachos | Kalina Bontcheva
Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016)
Stance Detection with Bidirectional Conditional Encoding
Isabelle Augenstein | Tim Rocktäschel | Andreas Vlachos | Kalina Bontcheva
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing
Isabelle Augenstein | Tim Rocktäschel | Andreas Vlachos | Kalina Bontcheva
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing
emoji2vec: Learning Emoji Representations from their Description
Ben Eisner | Tim Rocktäschel | Isabelle Augenstein | Matko Bošnjak | Sebastian Riedel
Proceedings of the Fourth International Workshop on Natural Language Processing for Social Media
Ben Eisner | Tim Rocktäschel | Isabelle Augenstein | Matko Bošnjak | Sebastian Riedel
Proceedings of the Fourth International Workshop on Natural Language Processing for Social Media
Numerically Grounded Language Models for Semantic Error Correction
Georgios Spithourakis | Isabelle Augenstein | Sebastian Riedel
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing
Georgios Spithourakis | Isabelle Augenstein | Sebastian Riedel
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing
Monolingual Social Media Datasets for Detecting Contradiction and Entailment
Piroska Lendvai | Isabelle Augenstein | Kalina Bontcheva | Thierry Declerck
Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC'16)
Piroska Lendvai | Isabelle Augenstein | Kalina Bontcheva | Thierry Declerck
Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC'16)
Entailment recognition approaches are useful for application domains such as information extraction, question answering or summarisation, for which evidence from multiple sentences needs to be combined. We report on a new 3-way judgement Recognizing Textual Entailment (RTE) resource that originates in the Social Media domain, and explain our semi-automatic creation method for the special purpose of information verification, which draws on manually established rumourous claims reported during crisis events. From about 500 English tweets related to 70 unique claims we compile and evaluate 5.4k RTE pairs, while continue automatizing the workflow to generate similar-sized datasets in other languages.
2015
Extracting Relations between Non-Standard Entities using Distant Supervision and Imitation Learning
Isabelle Augenstein | Andreas Vlachos | Diana Maynard
Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing
Isabelle Augenstein | Andreas Vlachos | Diana Maynard
Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing
USFD: Twitter NER with Drift Compensation and Linked Data
Leon Derczynski | Isabelle Augenstein | Kalina Bontcheva
Proceedings of the Workshop on Noisy User-generated Text
Leon Derczynski | Isabelle Augenstein | Kalina Bontcheva
Proceedings of the Workshop on Noisy User-generated Text
2014
Seed Selection for Distantly Supervised Web-Based Relation Extraction
Isabelle Augenstein
Proceedings of the Third Workshop on Semantic Web and Information Extraction
Isabelle Augenstein
Proceedings of the Third Workshop on Semantic Web and Information Extraction
2013
Search
Fix author
Co-authors
- Johannes Bjerva 16
- Arnav Arora 14
- Pepa Atanasova 11
- Ryan Cotterell 10
- Dustin Wright 10
- Nadav Borenstein 9
- Christina Lioma 8
- Anders Søgaard 8
- Lucie-Aimée Kaffee 5
- Sebastian Riedel 5
- Jakob Grue Simonsen 5
- Karolina Stanczak 5
- Andreas Vlachos 5
- Erik Arakelyan 4
- Kalina Bontcheva 4
- Preslav Nakov 4
- Anna Rogers 4
- Burcu Can 3
- Sagnik Ray Choudhury 3
- Spandana Gella 3
- Momchil Hardalov 3
- Yova Kementchedjhieva 3
- Sara Vera Marjanovic 3
- Pasquale Minervini 3
- Tim Rocktäschel 3
- Mattia Samory 3
- Indira Sen 3
- Claudia Wagner 3
- Srishti Yadav 3
- Haeun Yu 3
- Katharina von der Wense 3
- Ira Assent 2
- Serge Belongie 2
- Nikita Bhutani 2
- Matko Bosnjak 2
- Samuel Cahyawijaya 2
- Kyunghyun Cho 2
- Steffen Eger 2
- Desmond Elliott 2
- Edward Grefenstette 2
- Mareike Hartmann 2
- He He 2
- Alexander Miserlis Hoyle 2
- David Jurgens 2
- Maria Maistro 2
- Maximilian Mozes 2
- Zain Muhammad Mujahid 2
- Amalie Brogaard Pauli 2
- Edoardo Maria Ponti 2
- Sebastian Ruder 2
- Jingyi Sun 2
- Anej Svete 2
- Hanna Wallach 2
- Johannes Welbl 2
- Lawrence Wolf-Sonkin 2
- Natália da Silva Perez 2
- Miryam de Lhoneux 2
- Wil Aalst 1
- Mostafa Abdou 1
- Osama Mohammed Afzal 1
- Mirela Alhasani 1
- Maria Antoniak 1
- Rahul Aralikatte 1
- Dennis Assenmacher 1
- Mohit Bansal 1
- Anabela Barreiro 1
- Giannis Bekoulis 1
- Mehul Bhatt 1
- Eva Blomqvist 1
- Iacer Calixto 1
- Oana-Maria Camburu 1
- Yong Cao 1
- Kris Cao 1
- Giuseppe G. A. Celano 1
- Robin Chan 1
- Aditi Chaudhary 1
- Lucas Chaves Lima 1
- Canyu Chen 1
- Eleanor Chodroff 1
- Fabio Ciravegna 1
- Arman Cohan 1
- Edward Collins 1
- Alexis Conneau 1
- Mrinal Das 1
- Thierry Declerck 1
- Thomas Demeester 1
- Leon Derczynski 1
- Tim Dettmers 1
- Yoan Dinkov 1
- Kevin Du 1
- Chris Dyer 1
- Ben Eisner 1
- Aykut Erdem 1
- Shangbin Feng 1
- Fabian Flöck 1
- Michael Färber 1
- Revanth Gangi Reddy 1
- Silin Gao 1
- Albert Gatt 1
- Jiahui Geng 1
- Anna Lisa Gentile 1
- Mor Geva 1
- Gayane Ghazaryan 1
- Bela Gipp 1
- Eleonora Giunchiglia 1
- Dimitra Gkatzia 1
- Yevgeniy Golovchenko 1
- Behzad Golshan 1
- Ana González-Ledesma 1
- Riccardo Guidotti 1
- Iryna Gurevych 1
- Ivan Habernal 1
- Lovisa Hagström 1
- Chi Han 1
- Casper Hansen 1
- Christian Hansen 1
- Faiz Ghifari Haznitrama 1
- Casper Veistrup Helms 1
- Daniel Hershcovich 1
- Felix Hill 1
- Tallulah Jansen 1
- Heng Ji 1
- Jiho Jin 1
- Nora Kassner 1
- Fabio Kepler 1
- Jamie Kiros 1
- Natacha Klein Käfer 1
- Roman Klinger 1
- Elena Kochkina 1
- Anna Korhonen 1
- Bailey Kuehl 1
- Stefan Lazov 1
- Andrea Lekkas 1
- Piroska Lendvai 1
- Patrick Lewis 1
- Sha Li 1
- Manling Li 1
- Xiang Lorraine Li 1
- Maria Liakata 1
- Haijiang Liu 1
- Zhaoqi Liu 1
- Elena Lloret 1
- Kyle Lo 1
- Thomas Lukasiewicz 1
- Bodhisattwa Prasad Majumder 1
- Marta Marchiori Manerba 1
- Sandra Martinková 1
- Diana Maynard 1
- Andrew McCallum 1
- Hongyuan Mei 1
- Clara Meister 1
- Sabrina J. Mielke 1
- Sewon Min 1
- Dipendra Misra 1
- Jeff Mitchell 1
- Helena Moniz 1
- Lukas Muttenthaler 1
- Junho Myung 1
- Farhad Nooralahzadeh 1
- Franz Nowak 1
- Thomas Nyegaard-Signori 1
- Alice Oh 1
- Malte Ostendorff 1
- Liangming Pan 1
- Marcin Paprzycki 1
- Junyeong Park 1
- Siddhesh Milind Pawar 1
- Siddhesh Pawar 1
- Jiaxin Pei 1
- Aditya Pillai 1
- Barbara Plank 1
- François Portet 1
- A Pranav 1
- Shauli Ravfogel 1
- Abhilasha Ravichander 1
- Georg Rehm 1
- Marek Rei 1
- Xiang Ren 1
- Lucas Resck 1
- Nils Rethmeier 1
- Laura Rimell 1
- Thea Rolskov 1
- Aleksandr Rubashevskii 1
- Irene Russo 1
- Phillip Rust 1
- Paul Röttger 1
- Elizabeth Salesky 1
- Naomi Saphra 1
- Sheikh Muhammad Sarwar 1
- Cezar Sas 1
- Peter Schneider-Kamp 1
- Inhwa Song 1
- Georgios Spithourakis 1
- Pontus Stenetorp 1
- Zeerak Talat 1
- Wang-Chiew Tan 1
- Jörg Tiedemann 1
- Lucas Torroba Hennigen 1
- Josef Valvoda 1
- Maria Han Veiga 1
- Pat Verga 1
- Lakshmi Vikraman 1
- Lena Voita 1
- Ekaterina Vylomova 1
- David Wadden 1
- Xiaozhi Wang 1
- Dongsheng Wang 1
- Lu Wang 1
- Lucy Lu Wang 1
- Yuxia Wang 1
- Greta Warren 1
- Dirk Weissenborn 1
- Adina Williams 1
- Amelie Wührl 1
- Shuzhou Yuan 1
- Yuji Zhang 1
- Ziqi Zhang 1
- Ran Zhang 1
- Chen Zhao 1
- Wei Zhao 1
- Mike Zhou 1
- Dimitrina Zlatkova 1
- José GC de Souza 1
- Robert Östling 1